
目次
背景
- 負荷試験時にdeadlockがデータベースで発生して困ったのでメモ
- 背景としては、画像解析処理の為にサーバーで解析結果を保存するときに発生した
- そのdeadlockの時に調べたり改めて確認した時のメモ
前提
ソフトウェアアーキ
- 言語: Python
- サーバー
- APサーバー: FastAPI
- ASGIサーバー: Uvicorn
- Webサーバー: Nginx
- ORM:
- SQLAlchemy v2
- RDB:
- PostgreSQL
- Read Committed
サーバー構成
主に次の三つのサーバー(レイヤー)構造で処理をしている。
- FEサーバー
- APIリクエスト受付用のFEサーバー
- BEサーバー
- 解析リクエストをする、ブローカー用のBEサーバー
- 解析サーバー
- 解析処理を行うマイクロサービスのサーバー
処理フロー
- FEサーバーでAPIリクエストを受け取りSQSに貯める
- BEサーバーでSQSをポーリングする
- BEサーバーで解析の実行計画を決定する
- BEサーバーが解析用のマイクロサーバー群に解析を依頼する
- その結果を集めて、BEサーバーがデータベースに保存する
RDB全般
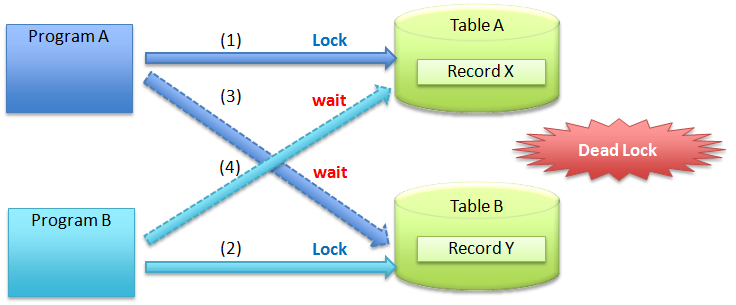
デッドロックとは
複数のプロセスやトランザクションが、互いに相手が持っているリソース(ロックなど)を待ち続けることで、永久に進行できなくなる状態のこと。
ロックモードの種類
PostgreSQL には 8種類のロックモードがある。
| ロックモード | 取得される操作 | 影響 |
|---|---|---|
| ROW SHARE | SELECT FOR UPDATE、SELECT FOR SHARE | DELETE をブロック |
| ROW EXCLUSIVE | UPDATE, DELETE, INSERT | ROW SHARE より強いロック |
| SHARE | LOCK TABLE IN SHARE MODE | UPDATE / DELETE は可能だが SHARE ROW EXCLUSIVE はブロック |
| SHARE ROW EXCLUSIVE | 特定の DDL | SHARE より強いが EXCLUSIVE より弱い |
| EXCLUSIVE | LOCK TABLE IN EXCLUSIVE MODE | すべての行の更新をブロック |
| ACCESS EXCLUSIVE | LOCK TABLE IN ACCESS EXCLUSIVE MODE | テーブル全体をロック(SELECT すらできない) |
クエリが作成するロックモード
各クエリにが作るロックは以下がある。
| SQL | ロックの種類 | 影響 |
|---|---|---|
UPDATE | 行ロック (ROW EXCLUSIVE) | 対象の行が他のトランザクションで UPDATE / DELETE されるのを防ぐ |
SELECT FOR UPDATE | 行ロック (ROW SHARE) | 対象の行を UPDATE / DELETE から保護する |
DELETE | 行ロック (ROW EXCLUSIVE) | 削除対象の行をロックし、他の UPDATE / DELETE をブロックする |
INSERT | 行ロック (ROW EXCLUSIVE) | 基本的には競合しないが、UNIQUE 制約があると競合する可能性あり |
LOCK TABLE IN EXCLUSIVE MODE | テーブルロック | 他のトランザクションが INSERT, UPDATE, DELETE できなくなる |
SELECT(普通の読み取り) | ロックなし | どのトランザクションも自由に読み取り可能 |
SELECT FOR UPDATEについて
- 注意なのは、
SELECT FOR UPDATEはSELECTに見えるが、実体はUPDATEに近い - 例えば、あるTXの
SELECT FOR UPDATEは他のTXのSELECT FOR UPDATEをブロックする - つまり、
SELECT FOR UPDATEは、実際は「UPDATEをしないUPDATE」 SELECT FOR UPDATEのロック開放はそのTXのCOMMIT時に解放される- ちなみに、
SELECT FOR UPDATEの最中にSELECTはすることができる - ただし、
READ COMMITEDではノンリピータブルリードやファントムリードが発生する可能性があるので注意
リード一貫性の問題(Read Consistency Issues)
リード一貫性の問題とは
Readの問題は次の3つがある。
| 問題 | 発生条件 | 影響 |
|---|---|---|
| ダーティリード(Dirty Read) | 未コミットのデータを他のトランザクションが読める | 読んだデータが後で ROLLBACK されると、データの整合性が崩れる |
| ノンリピータブルリード(Non-Repeatable Read) | 同じトランザクション内で、同じ SELECT でも結果が変わる(他のトランザクションの UPDATE / DELETE の影響) | 2回の SELECT で異なる値が見える |
| ファントムリード(Phantom Read) | 同じ SELECT でも、新しい行 (INSERT) が増えたり、削除されたりする | WHERE 条件に一致する行数が変化する |
ダーティーリードは
- 他Commit前のTXのCRUDの変更を読み込める事による問題
- 特に、Rollbackされると、データ不整合が発生する
| |
トランザクションBは、存在しないはずのデータ ‘Bob’ を見てしまったことになった。
ノンリピータブルリード
- 他コミット済みのTXのUD(UpdateやDelete)による問題
- UDによって、既存の行のデータが変わる(値が変わる or 消える)問題
| |
同じトランザクション内で SELECT した結果が変わる(ノンリピータブルリード発生)。
ファントムリード
- 他コミット済みのTXのCUD(InsertやUpdateやDelete)による問題
- CUDによって、結果セットの行数が変わる(新しい行が増える or 減る)問題
| |
- 検索結果の行数が変わってしまう(ファントムリード発生)
REPEATABLE READでは防げず、SERIALIZABLEにする必要がある
トランザクション分離レベルとReadの問題
トランザクション分離レベルのReadの関係
| 分離レベル | ダーティリード | ノンリピータブルリード | ファントムリード |
|---|---|---|---|
READ UNCOMMITTED | ❌ 発生する | ❌ 発生する | ❌ 発生する |
READ COMMITTED | ✅ 発生しない | ❌ 発生する | ❌ 発生する |
REPEATABLE READ | ✅ 発生しない | ✅ 発生しない | ❌ 発生する |
SERIALIZABLE | ✅ 発生しない | ✅ 発生しない | ✅ 発生しない |
- トランザクション内の一貫性を保ちたい(変更途中のデータを見たくない)
- => REPEATABLE READ / SERIALIZABLE
- スナップショットを維持し、一貫性を確保
- リアルタイムの最新データがほしい
- => READ COMMITTED
SELECTのたびに最新のCOMMIT済みデータを取得
- 未コミットのデータも見たい(※PostgreSQL では不可)
- => READ UNCOMMITTED
ACID特性
ACID特性 は、データベースのトランザクションが信頼性を持って処理されるために必要な4つの特性。
| 特性 | 説明 | 例 |
|---|---|---|
| Atomicity(原子性) | トランザクションは「すべて成功」または「すべて失敗」 | 送金処理の途中で失敗したら、残高は元のまま |
| Consistency(一貫性) | トランザクションの前後でデータのルールが守られる | 存在しない product_id を orders に挿入できない |
| Isolation(分離性) | 同時実行のトランザクションが影響し合わない | 在庫チェック中に他のトランザクションの変更が見えない |
| Durability(永続性) | COMMIT したデータは消えない | COMMIT 直後にDBがクラッシュしても、データは保証される |
逆に、ACIDを守らないと何が起こるか?
- 原子性がない
- 送金処理が途中で止まったら、お金だけ引かれて相手に届かない
- 一貫性がない
- 存在しない商品IDの注文が通る
- 分離性がない
- 他のトランザクションの影響で、データが意図しない値に変更される
- 永続性がない
COMMITしたのに、障害でデータが消える
デッドロックの例
データ用意
| |
次の時系列だと、2つのTX間でデッドロックが発生する。T1とT2のどちらもCommitはしていないから。
| TX | SQL コマンド | 意味 |
|---|---|---|
| T1 | BEGIN TRANSACTION; | トランザクション開始 |
| T1 | UPDATE users SET name = 'Alice Updated' WHERE id = 1; | id=1 の行をロック |
| T2 | BEGIN TRANSACTION; | トランザクション開始 |
| T2 | UPDATE users SET name = 'Bob Updated' WHERE id = 2; | id=2 の行をロック |
| T1 | UPDATE users SET name = 'Alice Final' WHERE id = 2; | id=2 のロックを待機(T2 がロック中) |
| T2 | UPDATE users SET name = 'Bob Final' WHERE id = 1; | id=1 のロックを待機(T1 がロック中) |
| PG | DEADLOCK DETECTED | デッドロック発生!どちらかのトランザクションが終了 |
Read Committedの場合、各 UPDATE 文ごとに行のロックを取得する仕様となっている。
共有ロックと排他ロック
- 共有ロック(Shared Lock、Sロック)
- 他のトランザクションが「読み取り」可能なロック
- 書き込み(更新・削除)を行うことはできない
- 排他ロック(Exclusive Lock、Xロック)
- 他のトランザクションが「読み書き」できなくなるロック
- 1つのトランザクションだけがデータを操作できる(単独アクセス)
ロック専用テーブルを利用する例
READ COMMITTEDで排他制御をしたい場合はロック専用テーブルを用意する方法もある- なお、テーブルは次を用意する
| |
Updateを使った排他制御
READ COMMITTEDなので、UPDATEの前にSELECTでLOCK STATUSをチェックすると、Non-repeatable readsの可能性が生まれる- 故に、UPDATE文は排他ロックを取得するため、その条件で
LOCK_STATUSを指定する事で排他制御が可能となる - さらに、
UPDATEの後にSELECTをすると、このTXによって更新されたのか、または既に別プロセスによってロックされていたのかを区別ができない- 更新が実際に行われたかどうかを知る唯一の方法が、
GET DIAGNOSTICSやRETURNINGになる
- 更新が実際に行われたかどうかを知る唯一の方法が、
- 何らかの理由で
LOCK_STATUSが1になりっぱなしになる対策として、LOCK_TIMEを見て、一定時間ロックされたらフラグを無視する - もし、処理に時間がかかる場合は、TTLであるLOCK_TIMEを更新して、他プロセスに処理をブロックされないようにする必要がある
ロック開始:
| |
解除:
| |
ただし、lockされている時にのみ解除する必要があるので注意。
SELECT FOR UPDATEを使った排他制御
SELECT FOR UPDATEを使うことも有効GET DIAGNOSTICSを使わなくても、LOCK_STATUS = '0'を指定しているので、SELECTの結果で分かる- デッドロックを避けたい場合やシーケンシャルな処理を担保したい場合、
nowaitやskip lockedが良い
| |
レコードがないと排他ロックは取れない
- そもそも大きな勘違いをしていた
- つまり、
select for updateで取得したデータが空の時は排他ロックはかからない- これが結論だった
- Aというレコードがないなら挿入する、ただし、2つ同じレコードを挿入したくはないというのが要件
- select for updateでAというレコードを探しても、同時に二つのプロセスからselect for updateがかかったら両方空になる
- 故に、両方のプロセスで空だからinsertしようとして重複するデータが挿入されて破綻する
- つまり、レコードがない状態がある場合は、排他ロックが取れないので、重複排除処理をSelect for updateでやるのは難しい
- それならロック専用テーブルを用意するしかない、もしくは、その重複したくないものでUniqueキーをつけるしかない
- アプリケーションレベルでのユニーク制約はロック専用テーブルを用意するしかない
部分インデックス
- mysqlでは後からユニーク制約をつけたい場合は、仮想カラムを追加して処理する方法もある
- しかし、Postgresの場合は、条件付きのインデックス(部分インデックス)が作れるのでそれが一番
- データマイグレーションもする必要もなく、条件付きでデータ整合性を保つことができる
- 例えば、次のような感じ
- created_at >= 2022-12-12 => xxxとyyyでは複合ユニークインデックス
AP周り
APレベルでのTX制御は難しい
フロー:
- Aを含むコードを
select for update - Aがなかったら、Aをインサート
- Commit
- つまり、Aというレコードを1つだけインサートしたい
- select for updateで対象のAのレコードがない時は排他ロックがかからずAをインサートする
- もし、そのコードを2つのプロセスから同時に実行したら、Aというレコードは2つインサートされる可能性がある
- なぜなら、排他ロックが両方で取れない為、両方Aをインサートする
これの解決策は、次の2つ:
- unique制約をつける
- ロック専用テーブルを用意して使う
PythonのAPログの強化
アクセスログ以外にも、デバッグログもJSON化した方が良かった。
| |
使う時
| |
結果
| |
アプリケーションバグ
以下のようなアプリケーションのバグや問題の可能性を確認した。
- txの貼り忘れ
- rollbackやcommit忘れ
- commitしたら排他ロックがリリースされるので、変更後に適切にcommit/rollbackされていない事を疑った
- 次の形で排他処理をまとめる所を囲って確実に実行されるように変更した
1 2 3 4 5 6 7 8try: pass except: await session.rollback() else: await session.commit() finally: await session.close()
- commitが早すぎた
- 途中で早すぎたcommitをしている事を疑った
- repositoryの読み間違い
- DDDで実装されているが、repository層でsessionを保持している
- それが、別sessionではないか疑った
- 不要なNestesd Transatction
- 一部がnested transactionだったので、それをシンプルに変えた
SAVEPOINTを作ると、ROLLBACK TO SAVEPOINTで戻せるが、シンプルに不要だった
- repositoryから取得したentityが古い疑惑
- repositoryから取得したentityが古い可能性がある
- そのため、既に同じentityがあっても、select for updateで取得したentityを利用した
- 状態チェックは初めに行うべき
- たとえ
SAVEPOINTを使っても、COMMITするとSAVEPOINTからではなくBEGINからのTX全体がCOMMITされるので注意 - 故に、最初に排他処理を入れるのが正解だった
- たとえ
- SQLAlchemyのオプション
auto_commitやauto_flushなど
- 排他ロックの回数の順序
- 2回排他ロックのSQLを実行しており、それらのSQLのTXによって実行順番が逆だとデッドロックになる
- もしくは、SQLは1回だったとしても、orderがバラバラだった場合はデッドロックになる
- TXの長さ
- 書き込む直前にTXを張り書き込むのがベター
- TXが長いと競合する可能性が高まるため
SQLAlchemy
SQLAlchemyのflushとcommit
- flush:
- SQLAlchemyのSessionが追跡している変更内容をデータベースに送信する操作
- 実際のSQLクエリが発行されるが、トランザクションはまだコミットされていない
- 主にセッション内での整合性チェックや、後続の処理で変更内容を参照したい場合に使用する
- commit:
- トランザクションを確定させ、変更内容を永続化する操作
- 自動的にflushが実行された後、トランザクションがコミットされる
- 変更内容は他のセッションからも参照可能になる
with session.begin():を抜けると自動的にcommitになる
SQLAlchemyのAuto Begin
SQLAlchemyhにはAuto Beginという機能がある。
| |
FastAPIのcontext managerの例
| |
ポイント
SELECT単体ではトランザクションは開始されないINSERT/UPDATE/DELETEで自動的にトランザクションが開始されるcommitの後は自動的に新しいトランザクションが開始される- 明示的なトランザクション管理(
withやbegin)も可能
SQLAlchemyのSelect for update
- select for updateを使うSQLAlchemyの例は以下
user = result.scalars().first()のタイミングでDBに問い合わせがかかり排他ロックがかかるresult = await session.execute(stmt)ではないので注意- また、commitしない場合は、他のtxはブロックされるので注意
- commitかrollbackのタイミングで他のTXが読み込めるようになる
| |
実行する場合
| |
PostgreSQL
Postgresのデバッグ方法
deadlock_timeoutの時間を上げるpg_stat_activityやpg_locksでデータを確認する
| |
その後、CLIをPSをチェックする。
| |
もしくは、pg_locksを見ても良い。
| |
Select for updateのオプション
no key- 弱いロック
- FKやIDXのKeyの更新しないかつ最新のselectが不要な場合は有効
no wait- ロックされてたらエラーで中断
- リトライ処理があるならこれでも良い
skip locked- ロックされてる行をスキップ
PostgresのCompatibility Matrix
Postgresの行レベルのロックの強さの比較表:
| Requested Lock Mode | FOR KEY SHARE | FOR SHARE | FOR NO KEY UPDATE | FOR UPDATE |
|---|---|---|---|---|
| FOR KEY SHARE | X | |||
| FOR SHARE | X | X | ||
| FOR NO KEY UPDATE | X | X | X | |
| FOR UPDATE | X | X | X | X |
see PostgreSQL: Documentation: 17: 13.3. Explicit Locking
NOTE:
- 「X」で競合する(後がブロックされる)事を意味する
- 対称行列になっている
PostgreSQLのログオプションの変更
設定確認
| |
すべてのステートメントをログに記録する。
| |
CLIから更新する。もしくは、RDSの場合は、パラメーターグループから更新する。
| |
結果は以下のようになる。
| |
分析ツールの利用
設定ファイル(postgresql.conf)を編集:
| |
サーバーを再起動:
| |
拡張機能を作成:
| |
デッドロックの 発生したクエリの履歴をpg_stat_statementsから取得:
| |
結論
次が大切だった:
- レコードはUpdateではなくInsertをメインに
- 並列分散処理のシステム設計としてはUpdateを前提とした処理フローは向いていなかった
- なぜなら、一貫性を持ったデータの更新には排他ロックをする必要があるため
- しかし、強い一貫性を持ったデータの構造にする必要はそもそもなかった
- さらに、順序処理を前提としてWaiting処理も入れていたため、それも複雑なシステムの一因だった
- 並列分散システムなので、フローはシンプルに
- そもそも排他処理はコストがかかるのでするべきではなかった
- 排他処理は沼なので、排他をやめてAPのバグやリファクタを先にすすめるべき
- 後々もっと長い時間でデータの結果整合性を合わせられるようにするべきだった
- Postgresのログからdeadlockの原因を突き止めるのは難しい
- 設定の確認
- SQLAlchemyの設定を深く理解するべき
- PostgreSQLの設定をデバッグ可能にする
- ローカルで再現するのを優先するべきき
- リファクタ・ファースト
- コードが複雑だと追っかけられないので、先に軽いリファクタをするべきだった。
- ログ・ファースト
- マイクロサービスのIn/Outのログも出すべき
- アクセスログだけではなく、一般のログもJSONで出すべき
- Don’t guess, just measure
参考文献
- 食事する哲学者の問題 - Wikipedia
- PostgreSQL: Documentation: 17: 13.3. Explicit Locking
- Is deadlock possible on first SELECT FOR UPDATE in transaction in PostgreSQL - Database Administrators Stack Exchange
- PostgreSQL FOR UPDATE vs FOR NO KEY UPDATE - Vlad Mihalcea
- ERROR: deadlock detected | Understanding deadlocks
- Debugging deadlocks in PostgreSQL | CYBERTEC PostgreSQL | Services & Support
- PostgreSQLのrow-level lockの動きについて #RDB - Qiita
- 5.4. 排他制御 — TERASOLUNA Global Framework Development Guideline 1.0.1.RELEASE documentation