
目次
背景
- DB設計や実装、SQL周りの備忘録
- SQLはMySQLやPostgresをベースにする
次のデータベースをこれでまで扱ってきたが、それらの詳細などは省く。
- NoSQL:
- MongoDB、Redis、Memcached、DynamoDB、ElasticSearch(OpenSearch)、datastore、InfluxDB
- RDS:
- SQLite、PostgreSQL、MySQL、PlanetScale
- NewSQL:
- CockroachDB
- BlockChain:
- Bitcoin、 Ethereum
DB設計
3つの設計
- 概念設計(Conceptual Design)
- 管理すべき情報を整理する
- 例: 顧客情報、注文情報などのエンティティを特定する
- 論理設計(Logical Design)
- RDBを使う前提でテーブルスキーマのの設計
- 例: 顧客テーブル、注文テーブルの関係を定義する
- 物理設計(Physical Design)
- 型やインデックス、制約、デフォルト値などの設計
- 例: 顧客IDのインデックスを設定し、検索パフォーマンスを向上させる
概念設計
次の三つを整理する。
- エンティティ
- 属性(アトリビュート)
- 関係(リレーション)
エンティティを出す方法
- 要件から名詞を書き出す
- その名詞の事物や事実、行為などの用語を書き出す
- 関連がありそうなモノをまとめる
また、この段階でER図を書くことがおすすめ。
リレーション
リレーションは3つのパターンがある。
- 1:多
- 芸能人と一般人のパターン
- 多が1を知る必要がある
- つまり、多が1のidを保持する
| |
- 多:多
- タグ付けのテーブルなどで使われるパターン
- 2次元では表現できないので、中間テーブルを用意する
| |
- 1:1
- 目的ごとに1つのテーブルを分けるパタン
- 意味論的と変更可能性を考慮して設計する
- 例えば、UserテーブルとそのUserのCredentialが合った場合
- UserがCredentialのIDを所有する
- 意味論的にusers.credential_idの方がcredentials.user_idより良いから
- もし、credentials.user_idにすると、credentailを作る時に、userが必要になるから
- ただし、今後の変更で1:多になるなら
- つまり、User:Credential = 1:多になる場合はCredentailがUserを知る必要がある
- スカラ値は正規化ではRDBでは許容されないから
| |
リレーションとアソシエーションの違い
- リレーション (Relation):
- テーブルそのものやテーブル間の関係を指す。
- データベースの構造的な要素。
- アソシエーション (Association):
- エンティティ間の論理的な関係を指す。
- オブジェクト指向やERMにおける関係性を示す。
つまり、リレーションはデータベース設計の物理的・構造的な観点を強調し、
アソシエーションはエンティティ間の論理的な関係性を強調する。
1:1のリレーションの4つの手法
他にもおすすめはしないが4つの1:1のリレーションの実現方法がある。
主キーを共有
| |
一方のテーブルに外部キーを持たせる
| |
両方のテーブルに外部キーを持たせる
| |
単一テーブルに統合する
| |
命名規則
カラムの命名規則
テーブル名
- ネームスペースでprefixをつける
- 例えば、
core_infra_usersみたいなスコープ付きの形
- 例えば、
- 複数形がベター
- 名前はsnake_caseにする
- 中間テーブルは
xxx_xxxと並べる- もしくは
xxx_mappingとする
カラム名の命名規則
- snake_caseにする
- 用途に合わせて命名規則を適用する
例
- id, xxx_id
- PK, FKのカラム
- xxx_cd, xxx_code, xxx_category
- カテゴリー、コード値のカラム
- xxx_by
- usernameのカラム
- xxx_at, xxx_time
- datetimeのカラム
- is_xxx
- boolのカラム
- xxx_status, xxx_type
- enumのカラム
- created_by, update_by, created_at, updated_at, deleted_at
- 鉄板のカラム名
制約は2文字でタイプを示してsqlalchemy的に命名する。
pk_<テーブル名>ix_<テーブル名>_<カラム名>fk_<テーブル名>_<参照先テーブル名>ck_<テーブル名>_<カラム名>uq_<テーブル名>_<カラム名>uq_<テーブル名>_<カラム名1>_<カラム名2>
ユニーク制約とユニークインデックスの違い
PostgreSQL 9.3.9において、両者には次の違いがある
- UNIQUE 制約を作る => UNIQUE INDEX も作られる
- UNIQUE INDEX を作る => UNIQUE 制約 は作られない
ただし、UNIQUE制約とUNIQUEインデックスのどちらを使用しても、指定されたカラムの値が一意であることを強制する点では同じ。
一般的には、データの一貫性を強制するためにUNIQUE制約を使用し、結果として自動的に対応するUNIQUEインデックスが作成される。
論理設計
論理設計は(RDB)に依存しない形で、次の三つを行う。
- リレーションの分解
- 1:N, N:1, N:Nの三つにリレーションはなる
- 中間テーブル(マッピングテーブル)に変換する
- キーの整理
- 主キー、外部キー、制約などを定義する
- 正規化
- 三つのステップで正規化をする
正規化
- 非正規化
- 正規化前のテーブル
- 第1正規化
- カラムの値をスカラーにする事
- 第2正規化
- 部分関数従属(キーの一部に対して従属する列)の排除
- 第3正規化
- 推移的関数従属の解消
正規化の例
第一正規化
第1正規形の定義は「1つのセルには1つの値しか含まれない」なので、スカラーに編子する。
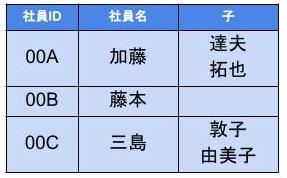
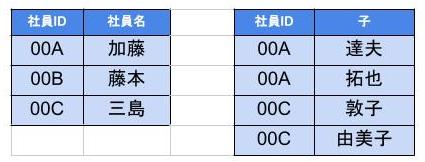
- すると以下のようになる
- この状態が関数従属性がない状態となる
- 正規化後は、以下のように関数従属が成立している
$$ {社員ID} → {社員名} {社員ID} → {子1} {社員ID} → {子2} $$
第二正規化
- 問題は、「会社名」だけは「会社コード」のみに従属している点
- つまり、部分関数従属になってしまっている
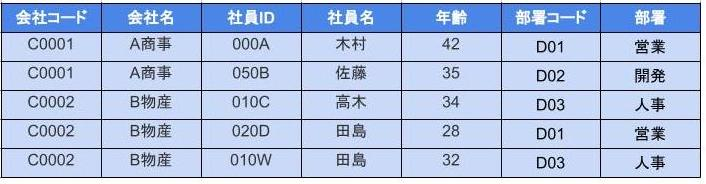
第2正規形はエンティティをテーブルごとに分割する作業という事。
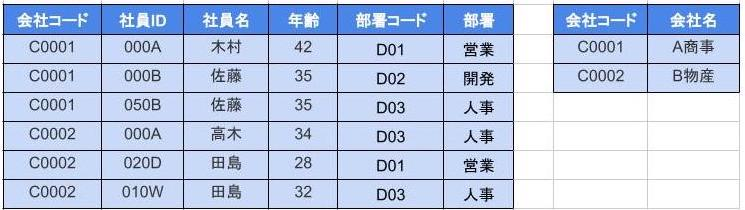
第三正規化
- 問題は推移的関数従属(段階的な従属関係)がある
- 具体的には次のように形式化できる
$$ {部署コード} → {部署} {会社コード、社員ID} → {部署コード} {会社コード、社員ID} → {部署コード} → {部署} $$
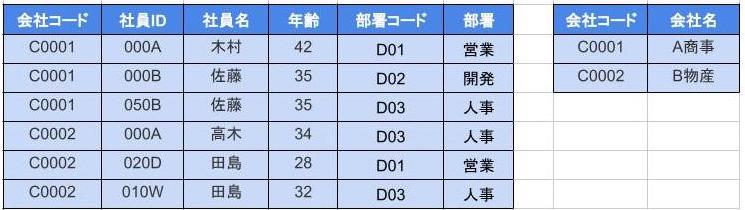
これにより、非キー列は主キー列に対してのみ従属するようになり推移的関数従属もなくなった。
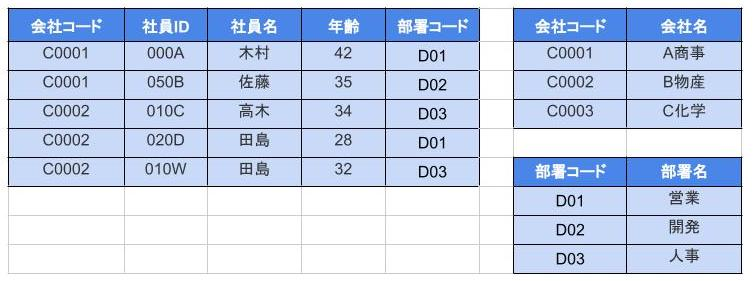
あえて非正規化する
- 非正規化は、データを冗長にすることで、クエリのパフォーマンスを向上させる方法
- 関連データを1つのテーブルにまとめることで、JOINを避けることができる
- JOINのボトルネックを避ける事で、パフォーマンス向上ができる
下はordersテーブルとcustomersテーブルを一つにまとめた非正規化の例。
| |
物理設計
論理設計で定義されたデータモデルを、特定のDBMS上で実装するための詳細な設計。
- テーブルの物理的なストレージ構造を定義する
- インデックス、パーティショニング、クラスタリング、データ圧縮などの物理的な最適化を行う
- DBMSの特定の機能を使用して、データの格納方法やアクセス方法を最適化する
テーブル設計書
エクセルでテーブル定義書を作るのがおすすめ。
テーブル設計仕様書
| 論理テーブル名 | 入出金行為 |
|---|---|
| 物理テーブル名 | payments |
| 作成日 | 20XX年10月10日(水) |
| 作成者 | Tanaka Taro |
カラムの定義
| # | PK | FK | 論理名 | 物理名 | 型(桁) | デフォルト | 例外 | 備考 |
|---|---|---|---|---|---|---|---|---|
| 1 | * | 入出金行為ID | id | bigint | NOT NULL | |||
| 2 | 日付 | created_at | DATE | NOT NULL | ||||
| 3 | * | 利用者ID | user_id | bigint | NOT NULL | |||
| 4 | 内容 | note | VARCHAR(100) | 不明 | NOT NULL |
パーテーション分割
大規模なテーブルを分割して管理し、クエリパフォーマンスとメンテナンスを向上させる。
- 水平分割(シャーディング)
- 大きなテーブルを複数の小さなテーブルに分割し、各テーブルを異なるサーバーに配置
- 例えばログテーブルなどは月ごとに分割しても問題がおきにくい
- 垂直分割
- テーブルの列を複数のテーブルに分割し、関連する列だけを含むテーブルを作成
- あえて関連するモノを別テーブルにまとめると、一括操作の管理が楽になる
水平分割の例。
| |
垂直分割の例。
| |
Indexの作成
インデックスを使用して、特定のクエリのパフォーマンスを向上させる。
| |
複合インデックス
| |
NOTE:
- 複合インデックスのカラムの順序は重要
- 最初のカラムがより選択的である場合、インデックスの効率が向上する
- 選択的とは=よりユニークであるという事
クラスタリング最適化
テーブルの物理的な並び順をインデックスに基づいて再編成し、範囲クエリのパフォーマンスを向上させる。
| |
データ圧縮の最適化
ストレージの使用量を削減し、I/Oパフォーマンスを向上させる。
| |
RDBのアーキ
MVCC
MVCCとは
- マルチバージョン並行制御 (MVCC: Multi-Version Concurrency Control) の略
- MVCCは、データベース管理システムにおいて、同時実行性を高めながら整合性を保つための技術
- PostgreSQLやMySQLなどのモダンなデータベースシステムで広く採用されている
なぜバージョンか?
- DBMS が既存の行を上書きしないというものです。代わりに、各 (論理) 行に対して、DBMS は複数の (物理) バージョンを維持するから
- 複数のクエリが、可能な場合は互いに干渉することなく、同時にデータベースの読み取りと書き込みを行えるようにすることが目的
MVCCの基本概念
- Snapshot isolation(SI):
- 各トランザクションは、自身の開始時点のデータベースの状態を「スナップショット」として取得する
- そして、そのスナップショットに基づいて読み取り操作を行う
- 他のトランザクションによる変更は影響を受けない
- バージョニング
- 各データの変更は、新しいバージョンを作成することで管理される
- データベースは、異なるバージョンのデータを保持し、適切なバージョンをトランザクションに提供する
- 非ブロッキングリード
- 読み取り操作はロックを使用せず、他のトランザクションがデータを書き込んでいる間でもブロックされない
- これにより、読み取りのパフォーマンスが向上する
- 書き込み競合の処理
- 書き込み操作は、データの現在のバージョンを確認し、競合が発生しない場合に新しいバージョンを作成する
- 競合が発生した場合、適切な処理(再試行やロールバックなど)が行われる
SIの例
ある6つのレコードのODD行をEVENタイプに、EVEN行をODDタイプにする例。
- シリアライザブルの場合は、常に順番が存在する
- 故に直列になり、後勝ちになる
- 結果、全てがODDもしくはEVENになる
- そのため、競合する
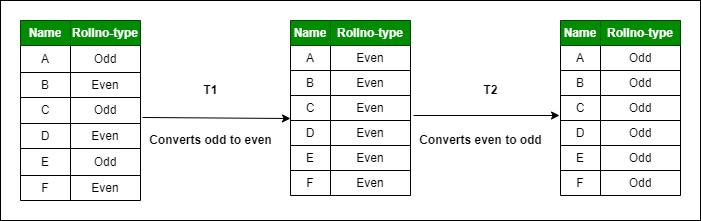
- 他方SIの場合は、スナップショットを取る
- そのスナップショットに基づき処理を行うので、他トランザクションの影響は起きない
- 2つに分かれるので、書き込み競合、ブロッキングリードが起きない
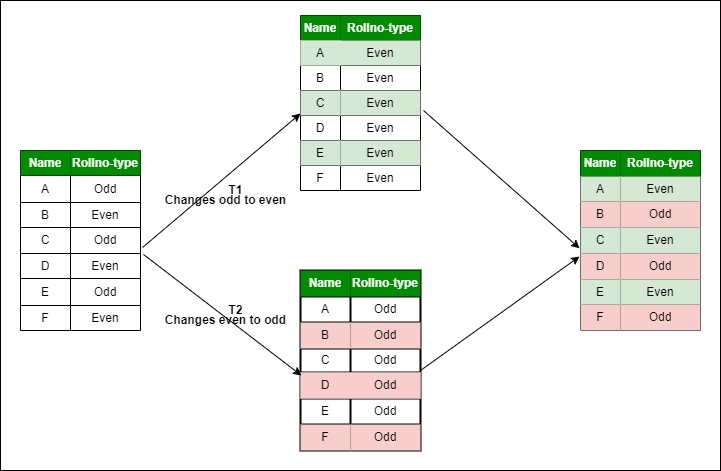
Multi-Versioned Storageの仕組み
- 例えば、yeraを1985 年から 1983 年に変更すると、新しいタプルが作成され、元のタプルは無効化される
- 用語
- データベース内部で各行をタプルと呼ばれる
- 複数のタプルが格納される単位の物理ブロックをページと呼ぶ
- タプルID(TID)は各行の物理的な位置を示すための識別子
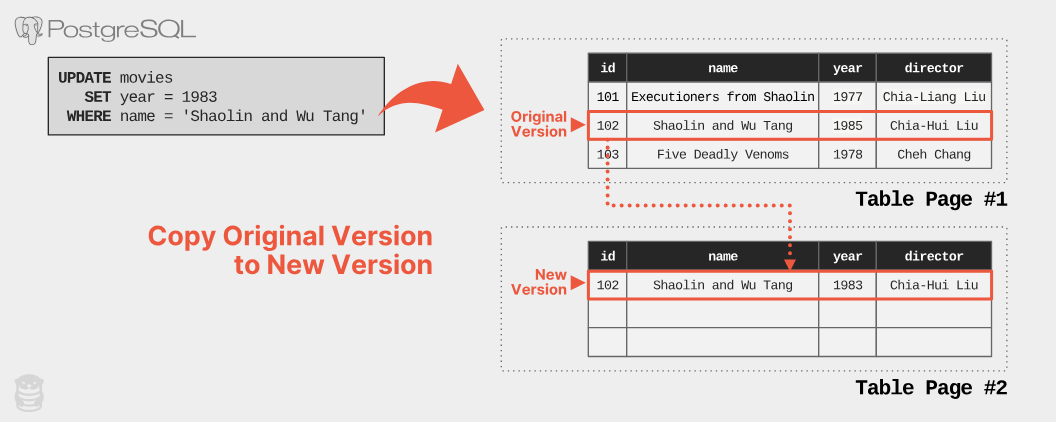
- 参照する際は、TIDに紐づくバージョンチェーンを使う
- version chainはリンクリストの構造を持ち、各タプルは次のバージョンへのポインタを持つ
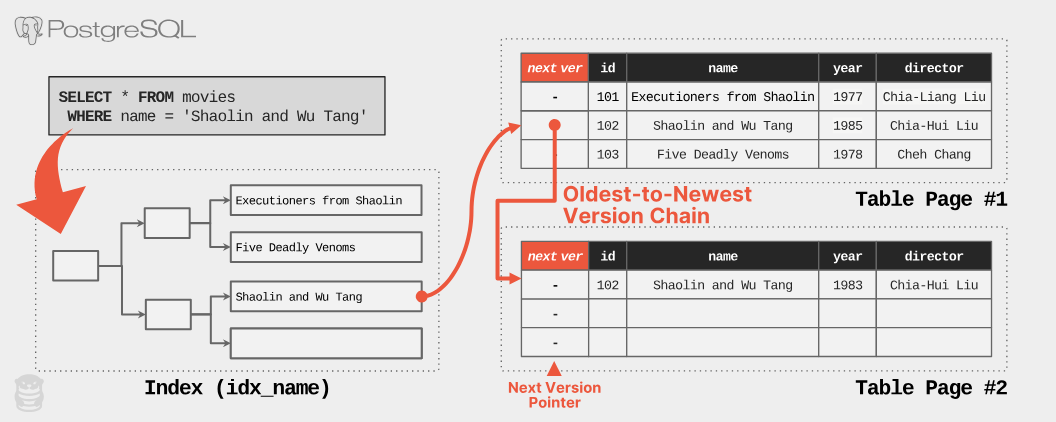
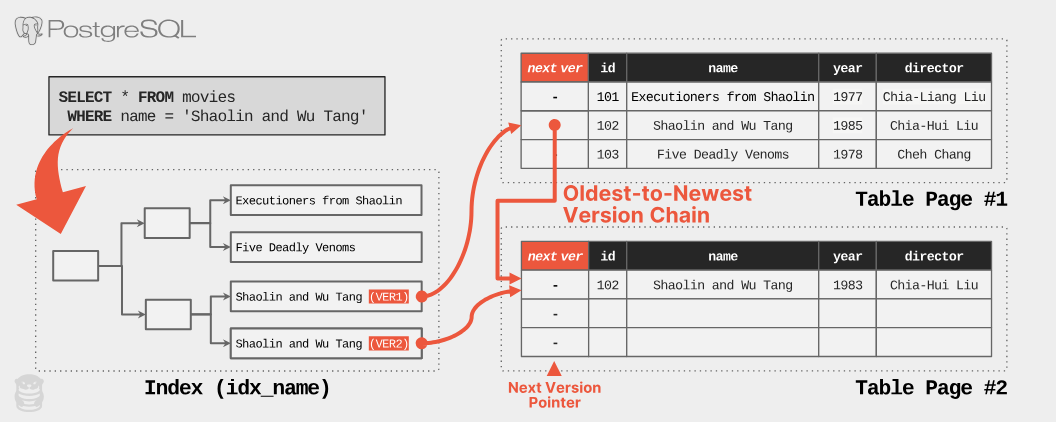
- 検索効率を向上させるため、インデックスが使用される
- インデックスにより、検索時の長いトラバースを避けることができる
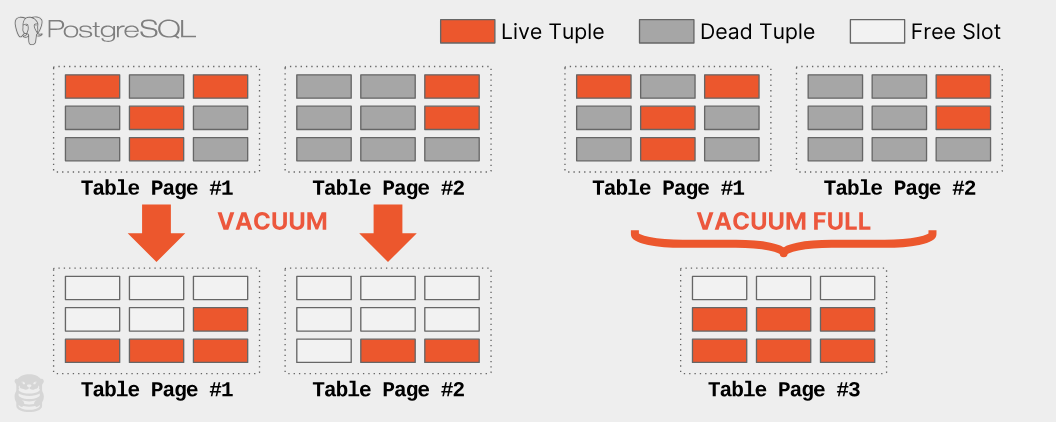
図の通り、不要なタプルが生まれるため、VACUUMコマンドによって回収する。
InnoDB vs. MyISAM
MySQLで選べるストレージエンジンの違い。
| 特徴 | InnoDB | MyISAM |
|---|---|---|
| トランザクション | サポート(ACID準拠) | サポートなし |
| 参照整合性 | 外部キー制約をサポート | サポートなし |
| ロック機構 | 行・テーブルレベルロック | テーブルレベルロック |
| クラッシュリカバリ | あり(自動リカバリ) | 限定的(手動リカバリ) |
| パフォーマンス | 書き込み多いワークロードに最適 | 読み取り多いワークロードに最適 |
| 追加機能 | MVCC、データ圧縮、バッファプール | 高速なフルテキスト検索、COUNT(*) 操作 |
| 使用例 | トランザクションが必要なシステム、データ整合性が重要なシステム | 読み取り専用のシステム、検索性能が重要なシステム |
InnoDBのデメリットはフルテキスト検索ができない点だが、正直そこはElasticSeachを使えばOK。
整合性
データベースシステムや分散システムにおいて3つの整合性のモデルがある。
強い整合性(Strong Consistency)
- 強い整合性とは、すべてのノードが常に最新のデータを持つ
- また、どのクライアントがどのタイミングでアクセスしても一貫したデータを読み取れることを保証する整合性モデル
- これは、直前の書き込みが完了してから次の読み取りが行われることを意味する
- 銀行の口座残高、在庫管理システムなど、データの一貫性が極めて重要なシステムで使用される
弱い整合性(Weak Consistency)
- 弱い整合性とは、システムがデータの一貫性を常に保証しない整合性モデル
- クライアントがデータを読み取るときに最新のデータが返される保証はなく、一貫性の要件が緩和されている
- ソーシャルメディアのフィード、キャッシュシステムなど、一貫性が重要ではないがスピードと可用性が重視されるシステムで使用される
- PostgreSQLのトランザクション分離レベルはRead Commitedなので弱い整合性に当たる
結果整合性(Eventual Consistency)
- 結果整合性とは、一時的にデータの不整合が許容されるものの、最終的にはすべてのノードが同じデータに収束する整合性モデル
- データの変更がすべてのレプリカに伝播し、最終的に一貫性が保たれる
- 読み取り操作は最新のデータを返すとは限らないが、最終的に一貫したデータに収束する
- DNSシステム、電子メールシステムなど、短期間のデータ不整合が許容されるシステムで使用される
結果整合性の比較
データの整合性で言うと次の順番になる。
$$ 強い整合性 > 結果整合性 > 弱い整合性 $$
メリットとデメリットの比較は次。
| 整合性モデル | メリット | デメリット |
|---|---|---|
| 強い整合性 | 常に最新のデータを保証 | - レイテンシが増加する、可用性が低下する可能性がある |
| 弱い整合性 | 高速な読み取りを提供、高い可用性を提供 | - データの一貫性が保証されない、古いデータが返されることがある |
| 結果整合性 | 高い可用性を提供、高いスループットを提供 | - 一時的な不整合が発生する、最終的な一貫性までに時間がかかることがある |
結果整合性の例
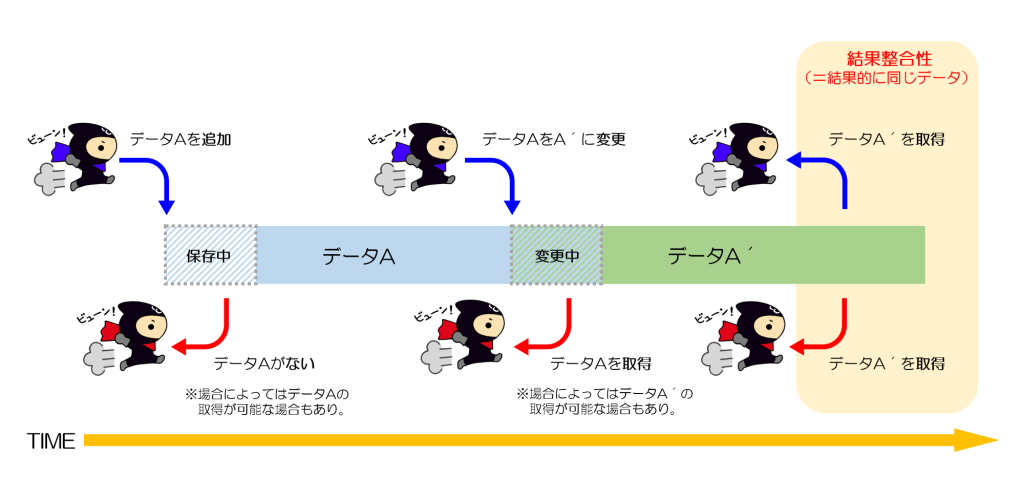
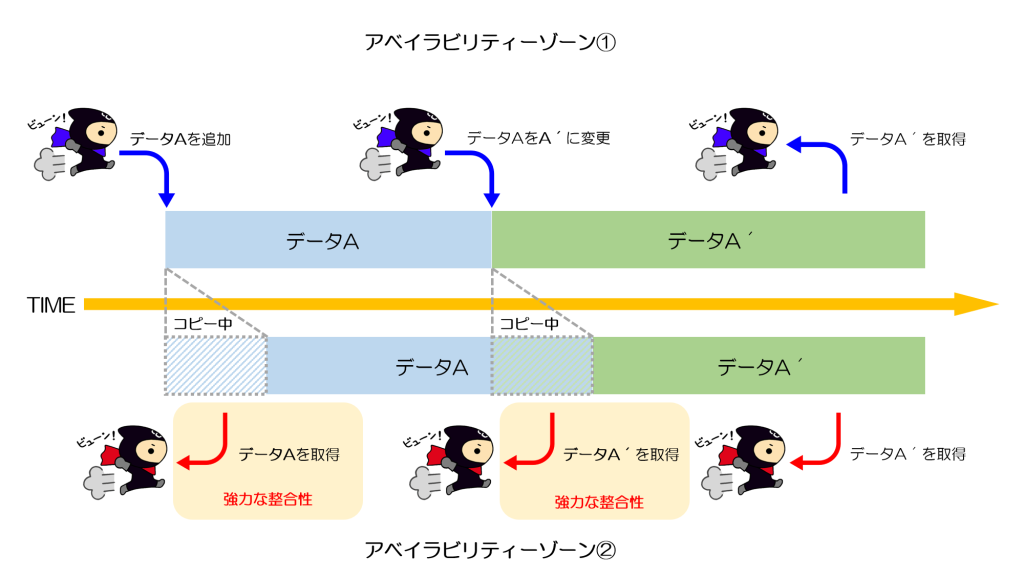
AWS S3が結果整合性のモデルだったが強いな整合性に変わった。その違いが分かりやすい。
結果整合性モデルなので、「時間はかかるかもしれないけど最終的にはデータの整合性は取れるよ」というのが元々の仕組みだった。
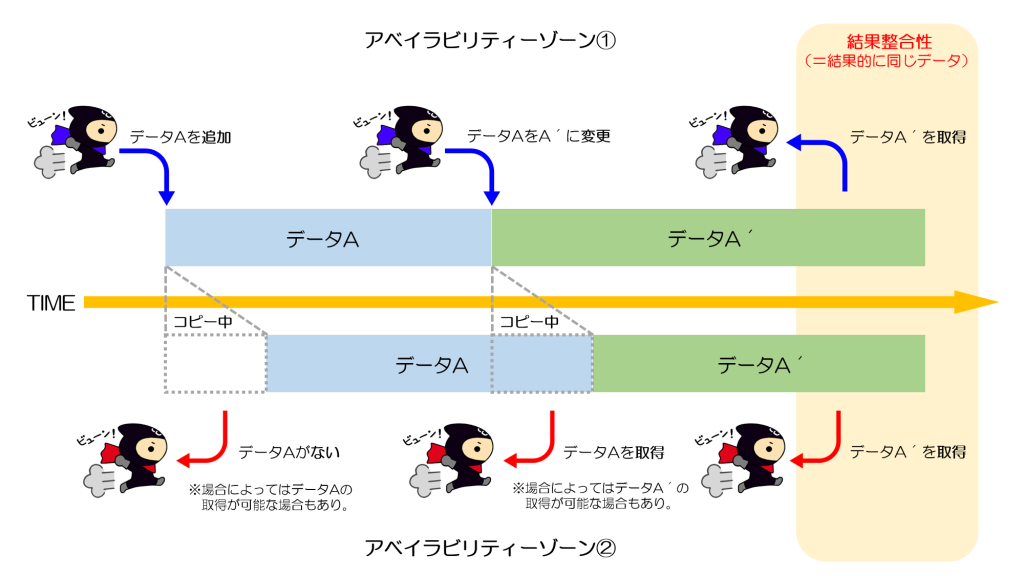
故に、取得したデータが完全に正しいかは保証がなかった。
強い結果整合性になったので、「データを追加したり更新したりした直後でも、最新の情報にアクセスできる」という仕組みになった。
CAP定理
CAP定理(CAP Theorem)は、分散データベースシステムが同時に以下の3つの特性を満たすことができない定理。
- C: Consistency(一貫性)
- すべてのノードが常に同じデータを持つこと
- A: Availability(可用性)
- すべての要求が成功または失敗の応答を返すこと
- P: Partition tolerance(分断耐性)
- システムがネットワークの分断(パーティション)に耐えること
これに基づき、システムは以下のいずれかの組み合わせを選ぶ必要がある。
- CA(Consistency and Availability)
- 分断耐性がない(単一のノードシステム)
- CP(Consistency and Partition Tolerance)
- 可用性が制限される可能性がある
- AP(Availability and Partition Tolerance)
- 強い整合性が制限される
インデックス
B-tree index
B-Treeの流れ
いくつかのデータ構造を説明する。
- リスト
- 直列でつながるデータ構造
- 二分木(binary tree)
- 木構造(ツリー構造)のうち、どの親ノードも二つ以下の子ノードを持つもの
- 平衡木(バランスドツリー)
- 木構造は単一の根ノードを起点に「親ノードは複数の子ノードを持つことができる」という規則に従ってノードを連結したデータ構造
- 挿入、削除、および検索操作を効率的に行うために設計された木
- 平衡二分木(balanced binary tree)
- 二分木を平衡にした構造
- AVL木
- 「どのノードの左右部分木の高さの差も1以下」という条件を満たす木
- ノードの回転操作によってバランスを保つ
- B-tree
- 「1つのノードがm個 (m>=2) の子ノードを持つことができる」という条件を満たす木
- AVL木を一般化したような木
- ノード分割や結合によってバランスを保つ
直列のツリーと平衡木
- リストは探索に$O(n)$かかる
- 他方、平衡木は節点の挿入/削除・探索どれもO(logN) で済む
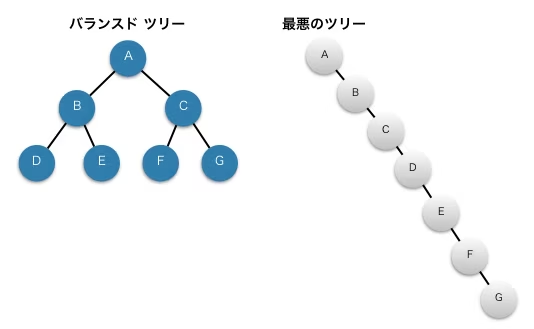
- 例えば、下の9の右に10が挿入されたとき、節点8から見た右部分木は2(9,10)になる
- しかし、左部分木は0や2からは高さが2になる
- 故に、AVL木の条件を満たさないため、再構成する必要がある
- AVL木は回転操作をし、高さを制約である1以下にする
- それとは実際には違うが、このようにノード分割や結合によってバランスを保つのがB-tree
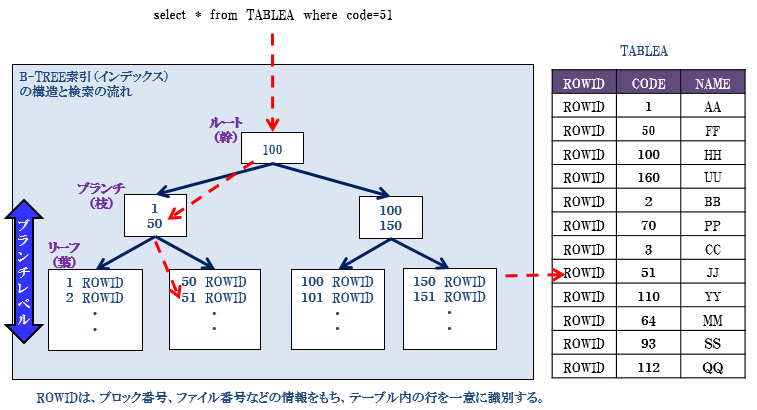
- 検索は下記のようにタプル(行)に対して検索が行われる
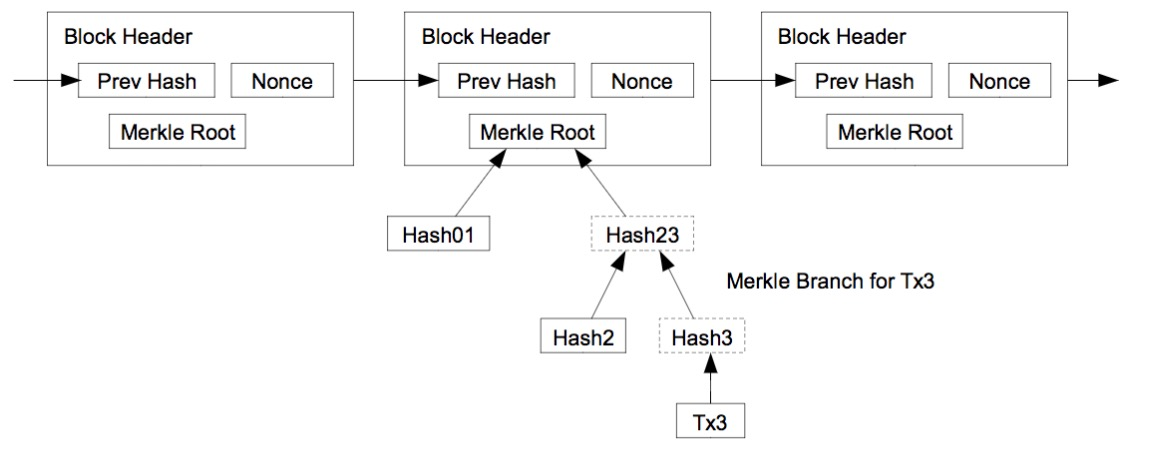
マークルツリー
- ちなみに、ブロックチェインではデータの整合性の為にマークルツリーが利用されている
- マークルツリーの頂点がマークルルートであり、全部のトランザクションを要約したモノとなる
- これによってblockのIDであるhashが最新のデータが改ざんされていないかの高速な検証が可能になる
基本的な構文
4つのSQLカテゴリー
RDBには4つのSQLカテゴリーが定義されている。
DDL(Data Definition Language)
データ定義言語は、データベースオブジェクト(テーブル、インデックス、ビュー、スキーマなど)の定義と管理を行う。
- CREATE: 新しいデータベースオブジェクトを作成
- ALTER: 既存のオブジェクトを変更
- DROP: 既存のオブジェクトを削除
- TRUNCATE: テーブルの全データを削除(構造は保持)
DML(Data Manipulation Language)
データ操作言語は、データベース内のデータの操作を行う。
- SELECT: データの検索と取得
- INSERT: 新しいデータの挿入
- UPDATE: 既存のデータの更新
- DELETE: 既存のデータの削除
DCL(Data Control Language)
データ制御言語は、データベースのアクセス制御と権限管理を行う。
- GRANT: ユーザーに権限を付与
- REVOKE: ユーザーから権限を剥奪
TCL(Transaction Control Language)
トランザクション制御言語は、トランザクションの管理を行う。
- COMMIT: トランザクションの変更を確定
- ROLLBACK: トランザクションの変更を取り消し
- SAVEPOINT: トランザクション内の保存ポイントを設定
- SET TRANSACTION: トランザクションの特性を設定
データ定義言語(DDL)
DDLは、データベーススキーマを定義および管理するために使用される。
CREATE
テーブルの作成
| |
ALTER
テーブルの変更
| |
DROP
テーブルの削除
| |
データ操作言語(DML)
DMLは、データベース内のデータを操作するために使用される。
SELECT
データの取得
| |
- 特定の列の取得
| |
- 条件付きのデータ取得
| |
INSERT
データの挿入
| |
UPDATE
データの更新
| |
DELETE
データの削除
| |
データ制御言語(DCL)
DCLは、データベースに対するアクセス権限を制御するために使用される。
GRANT
権限の付与
| |
REVOKE
権限の剥奪
| |
トランザクション制御言語(TCL)
TCLは、トランザクションの制御を行うために使用する。
BEGIN
トランザクションの開始
| |
COMMIT
トランザクションの確定
| |
ROLLBACK
トランザクションの取り消し
| |
関数と集約
集約関数
SUM, AVG, COUNT, MAX, MIN
| |
グループ化
GROUP BY
| |
条件付き集約
HAVING
| |
結合(JOIN)
内部結合
INNER JOIN
| |
外部結合
LEFT JOIN
| |
RIGHT JOIN
| |
クロス結合
CROSS JOIN
| |
サブクエリ
サブクエリの使用
| |
インデックス
インデックスの作成
| |
ビュー
ビューの作成
| |
トリガー
トリガーの作成
| |
指定順序と実行順序
| 指定順序 | 実行順序 | 句 | 内容 |
|---|---|---|---|
| 2 | 1 | FROM(JOINも含む) | 実行対象のテーブルを指定する |
| 3 | 2 | WHERE | テーブルに対してレコードの抽出条件を指定する |
| 4 | 3 | GROUP BY | レコードをグループ化する |
| 5 | 4 | HAVING | グループ化した結果に対して抽出条件を指定する |
| 1 | 5 | SELECT | 取得(表示)する列を指定する |
| 6 | 6 | ORDER BY | 取得した列を並び替える |
その他
エイリアス
- エイリアス(as)は省略可能
InとBetweenの使い分け
- 複数の値に対して同じ条件をチェックする場合、IN を使う
- また、範囲をチェックする場合は BETWEEN を使う
| |
Case句
| |
集合系
集合操作
SQLの集合の操作とは、テーブルから取得した結果セットに対して、和集合、積集合、差集合などの操作を行う事。
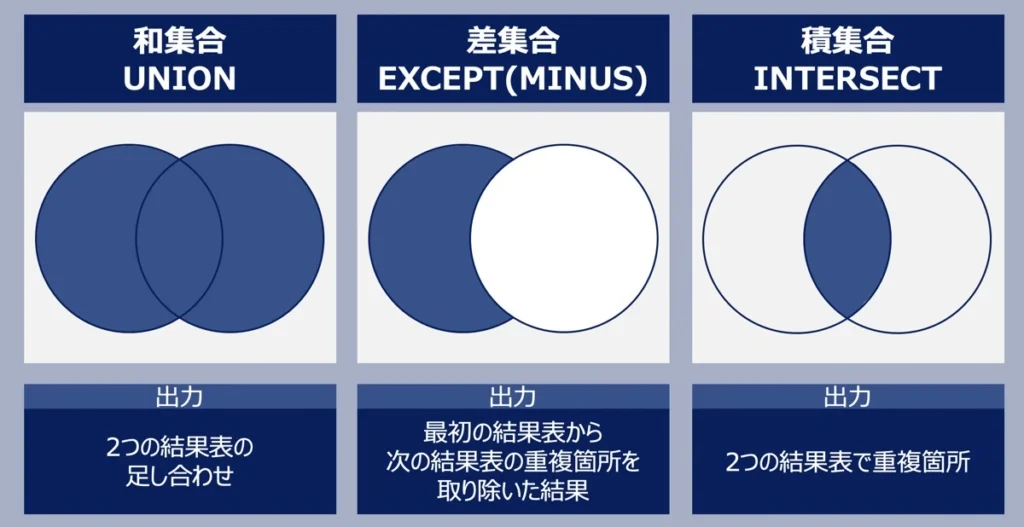
和集合
$$ BLUE + RED $$
重複を削除する場合
| |
重複を削除しない場合
| |
積集合
$$ BLUE - RED $$
| |
差集合
| |
重複排除
| |
部分集合
| |
部分集合
集計系
Group by
指定した列に基づいて行をグループ化し、そのグループごとに集計を行う。
| |
selectに指定できるのは次の3パターン。
- group byで指定したカラム
- 集計関数
- 定数
Window
- 元の行を消さずに、集計関数を使って行ごとに結果を計算する
- 下のクエリは、各従業員の部門ごとの平均給与を計算し、それを元の行と共に表示する
- 下の
PARTITION BY department_idがgroup by department_idに相当する - つまり、元のemployeesは維持される
| |
ウィンドウ関数には、次の関数などがある。
- ROW_NUMBER()
- 各行に一意の番号を振る
- RANK()
- 値に順位を付け、同じ値には同じ順位を振る
- なお、次の順位はスキップされる
- DENSE_RANK()
- 値に順位を付け、同じ値には同じ順位を振る
- 次の順位はスキップされない
- SUM()
- 累積合計を計算する
- AVG()
- 平均値を計算する
- OVER()
- ウィンドウの指定を行う
JOIN
基本
- 複数のテーブルを結合して関連するデータを取得するための手段
| |
Apply演算子
Apply演算子とは
- APPLY 演算子は、SQL Serverで提供される特有の演算子
- APPLY 演算子は、左側のテーブルの各行に対して右側のテーブル関数を適用し、その結果を結合する
- つまり、行ごとに異なるサブクエリを実行することができる
- ただし、これは結局Outer Joinと同じなのでApplyを使わなくても大丈夫である
Applyの例
業員テーブル(employees)とその従業員のプロジェクトを管理するテーブル(projects)があると仮定する。
| |
- 従業員ごとに、その従業員が担当するプロジェクトを取得するクエリは次となる
- CROSS APPLY を使用すると、各従業員のプロジェクトが取得される
| |
データを準備する。
| |
実行結果
| employee_id | first_name | project_name |
|---|---|---|
| 1 | John | Project A |
| 1 | John | Project B |
| 2 | Jane | Project C |
ただし、これは結局Left Outer Joinと同じなので、outer joinさえ分かっていればよい。
18のJoinテクニックの詳細
18のJoinテクニックとは
- 18個のMSのTSQLのテクニック
- TSQLでは多くのJOINタイプがあり、それぞれ異なる状況に応じて適切に選択する必要がある
- 各JOINは、特定の状況で適切に使用することで、必要なデータを効率的に取得することができる
- MySQLやPostgreSQLでも応用ができる
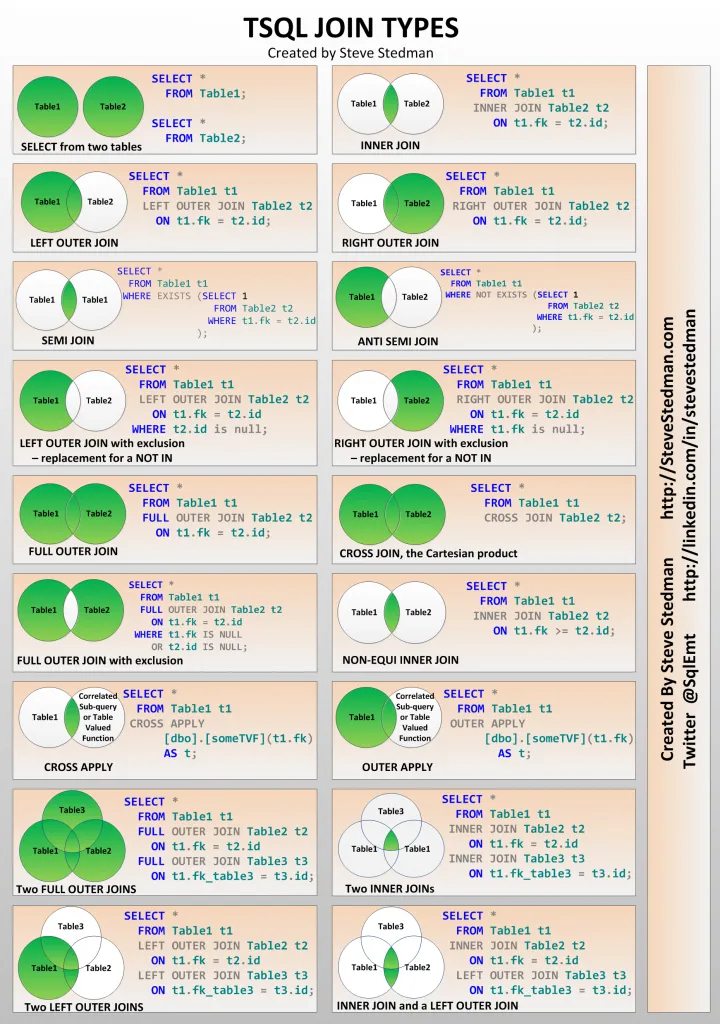
SELECT from two tables
2つのテーブルからデータを単純に取得する場合、それぞれ個別にSELECT文を使用。
| |
INNER JOIN
- INNER JOINは、両方のテーブルに共通するデータのみを取得
- 内部結合には共通のキーが必要
| |
LEFT OUTER JOIN
- LEFT OUTER JOINは、左側のテーブルの全データと、右側のテーブルの一致するデータを取得
- 右側のテーブルに一致するデータがない場合、NULLが返される
| |
RIGHT OUTER JOIN
- RIGHT OUTER JOINは、右側のテーブルの全データと、左側のテーブルの一致するデータを取得
- 左側のテーブルに一致するデータがない場合、NULLが返される
| |
FULL OUTER JOIN
FULL OUTER JOINは、両方のテーブルの全データを取得し、どちらか一方にしかないデータにはNULLが返される。
| |
CROSS JOIN(交差結合)
- CROSS JOINは、両方のテーブルの全ての組み合わせを生成する
- データの掛け算のようなもの
- CROSS JOINは、2つのテーブルのすべての組み合わせを返す
- 結合条件はない
| |
SEMI JOIN(半結合)
- SEMI JOINは、左側のテーブルから右側のテーブルに一致する行が存在する場合、その行のみを取得
- INNER JOINは、結合条件に一致する両方のテーブルの行を取得するが、Semi joinは片方のみ
| |
ANTI SEMI JOIN(反半結合)
- ANTI SEMI JOINは、左側のテーブルから右側のテーブルに一致しない行のみを取得する
- ANTI SEMI JOINはマスターなのにFKとして使用されていないモノのみを取るイメージ
| |
APPLY(適用)
CROSS APPLY(交差適用)
1SELECT * FROM Table1 t1 CROSS APPLY (SELECT * FROM Table2 t2 WHERE t1.fk = t2.id) AS t;CROSS APPLYは、左側のテーブルの各行に対して右側のテーブルのサブクエリを適用。
OUTER APPLY(外部適用)
1SELECT * FROM Table1 t1 OUTER APPLY (SELECT * FROM Table2 t2 WHERE t1.fk = t2.id) AS t;OUTER APPLYは、左側のテーブルの各行に対して右側のテーブルのサブクエリを適用し、一致する行がない場合はNULLを返す。
複合JOIN
Two FULL OUTER JOINs(2つの完全外部結合)
1SELECT * FROM Table1 t1 FULL OUTER JOIN Table2 t2 ON t1.fk = t2.id FULL OUTER JOIN Table3 t3 ON t1.fk_table3 = t3.id;3つのテーブル間で完全外部結合を行う。
Two INNER JOINs(2つの内部結合)
1SELECT * FROM Table1 t1 INNER JOIN Table2 t2 ON t1.fk = t2.id INNER JOIN Table3 t3 ON t1.fk_table3 = t3.id;3つのテーブル間で内部結合を行う。
INNER JOIN and a LEFT OUTER JOIN(内部結合と左外部結合)
1SELECT * FROM Table1 t1 LEFT OUTER JOIN Table2 t2 ON t1.fk = t2.id LEFT OUTER JOIN Table3 t3 ON t1.fk_table3 = t3.id;内部結合と左外部結合を組み合わせてデータを取得する。
サブクエリ
基本
サブクエリの構文
- サブクエリは、括弧
()で囲まれ、通常はSELECT文の中に含める - SELECT文、FROM句、WHERE句などで使われる
| |
サブクエリの使いどころ
- フィルタリング:
- 特定の条件に一致するデータを抽出する際に使用
- where句と
in句でサブクエリを使うなど
- 集計:
- 集計関数と組み合わせて、特定のグループに対する集計結果を利用する場合
- 複数行返すサブクエリをWhere句と
AVG句と共に利用するなど
- 比較:
- 比較演算子と一緒に使用して、条件を満たすかどうかを確認する
=,>,<,!=など
- データの挿入、更新、削除:
- 複数のテーブルからのデータを使って操作を行う際に使用される
- INSERT, UPDATE, DELETE文で利用するなど
サブクエリを使用した例
全ての従業員の名前と給与を表示すが、給与がその従業員の部門の平均給与以上の人のみを対象とするクエリ。
| |
また、In句との相性も良い。
| |
サブクエリの種類
単一行サブクエリ
- 結果が1行1列のみを返すサブクエリ
| |
複数行サブクエリ
- 複数の行を返すサブクエリ
- IN, ANY, ALL演算子と一緒に使うことが多い
- 下の例は普通のサブクエリなので、サブクエリに引数がないので1度だけ実行される
| |
相関サブクエリ
- 外側のクエリの結果に依存するサブクエリ
- サブクエリ内で外側のクエリの列を参照する
- サブクエリの引数(下の例だと
e1.department_id)があるため、引数が変わったタイミングで実行される
| |
自己相関サブクエリ
- 各行ごとに個別に評価されるのでパフォーマンスは良くない
| |
ネストされたサブクエリ
- サブクエリ内にさらにサブクエリを含む場合
| |
サブクエリの代替
CTE(共通テーブル式)とは
- WITH句を使用して共通テーブル式を定義することがベター
- サブクエリは複数回評価される可能性があるが、CTEは一度だけ評価されるため、複数回の計算を避けることができ、効率的
- また、サブクエリは再帰的に使用する事ができないが、CTEは再帰的に使用できるため、階層構造や親子関係のデータを扱うのに便利
- 簡単なフィルタリングならサブクエリでもOK
サブクエリの場合
| |
CTEの場合
| |
Viewとは
- ビューは仮想的なテーブルとして定義され、データベース内に保存される
- ビュー自体にデータは保持されないが、基になるテーブルのデータを参照する
- 基になるテーブルの構造を隠し、特定の列やデータだけを公開することができ、データの抽象化が可能
| |
Viewとセキュリティ
- サブクエリは一時的なものでそのクエリ内でのみ有効だが、ビューはデータベースに保存され、複数のクエリで再利用可能
- また、ビューは特定の列やデータだけを公開することで、セキュリティを強化する手段として使用もできる
元テーブル
| |
ビューの作成:
| |
ビューの利用
| |
こうする事で次の2つができる。
- 特定の行のみ参照
- 特定の列のみ参照
また、ビューの権限設定をする事でユーザーごとの認証も可能。
| |
user_roleというロールに対してpublic_employeesビューへのSELECT権限を付与する事ができる- これによって、そのロールに属するユーザーはビューを通じてデータにアクセスできるようになる
Materialized View
- Materialized Viewはクエリの結果を物理的に保存するビュー
- 通常のビューがクエリの定義を保存だけだが、Materialized Viewは実際のデータも保存する
- そのため、複雑なクエリを高速化することができる
- ただし、データは基となるテーブルが更新されたときに自動的に更新されるわけではないので注意
| |
データのリフレッシュ
| |
トランザクション
トランザクション分離レベル
標準SQLの分離レベル
- トランザクション分離レベルは4つある
- Postgresのデフォルトはリードコミッティド
- つまり、1回目のリードでは、最新を取得できるという事
| 分離レベル | ダーティリード | 反復不能読み取り | ファントムリード |
|---|---|---|---|
| リードアンコミッティド | 可能性あり | 可能性あり | 可能性あり |
| リードコミッティド | 安全 | 可能性あり | 可能性あり |
| リピータブルリード | 安全 | 安全 | 可能性あり |
| シリアライザブル | 安全 | 安全 | 安全 |
- リードアンコミッティド(Read Uncommitted)
- 他のトランザクションがコミットしていない変更を読み取ることができる
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
- リードコミッティド(Read Committed)
- 他のトランザクションがコミットした変更のみを読み取る
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
- リピータブルリード(Repeatable Read)
- トランザクションが開始された後に他のトランザクションがコミットした変更を読み取らない
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
- シリアライザブル(Serializable)
- トランザクションが完全に順序付けられたかのように実行される。最も厳密な分離レベルであり、並行トランザクションによる影響を受けない
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
禁止される現象
次の3つの現象が発生する恐れがある。
- ダーティリード
- 同時に実行されている他のトランザクションが書き込んで未だコミットしていないデータを読み込んでしまう事
- 反復不能読み取り
- トランザクションが、以前読み込んだデータを再度読み込み、
- そのデータが(最初の読み込みの後にコミットした)別のトランザクションによって更新されたことを見出す事
- ファントムリード
- トランザクションが、複数行のある集合を返す検索条件で問い合わせを再実行した時、
- 別のトランザクションがコミットしてしまったために、同じ検索条件で問い合わせを実行しても異なる結果を得てしまう事
Serializable分離の仕組み
- Serializableではネクストキーロックを行う
- つまり、行ロックとギャップロックをかけているという事
- 具体的には、selectにselect for updateをかけいるようなモノ
- その間は排他処理になるので、トランザクション間でデータ整合性が保たれる
PostgreSQLのREAD COMMITTEDの注意
- PostgresのデフォルトはRead Commited
- なので、ダーティーリード(他のトランザクションのcommit前の変更の読み取り)は発生しない
- また、1回目のクエリは常に最新になる
- しかし、二回同じクエリを発行する際は注意
- 反復不能読み取りで、同じトランザクションの中で、2回目の結果が変わる事がある
- ファントムリードで、同じトランザクションの中で、複数読み取りの結果が変わる事がある
原始性、一貫性、隔離性、耐久性(ACID特性)
- 信頼性のあるトランザクションシステムの持つべき性質として定義した概念
- トランザクション分離性は他のトランザクションに影響を与えない性質
原子性 (Atomicity)
- トランザクション内の操作が全て実行されるか、または全て実行されないかのどちらかになる
- 中途半端な状態は有り得ないです
- つまり、トランザクションはそれ以上細かい単位に分割することができない作業単位であるということ
一貫性 (Consistency)
トランザクションの実行前と後でデータに矛盾がなく整合性が保たれる性質
分離性 (Isolation)
- トランザクション中に行われる操作は他のトランザクションに影響を与えない性質
- つまり、それぞれのトランザクションは分離された状態で操作を行わなければならない
永続性 (Durability)
- トランザクションが完了すると、その処理結果は永続的となる
- たとえシステム障害が発生してもデータが失われることがない性質
サブトランザクション
サブトランザクションの方法
- サブトランザクションは入れ子になったトランザクションの事
- サブトランザクションを使いたい場合は次のようにSavepointでできる
- 入れ子にするSavepoint内でのサブトランザクションのrollbackも可能
- ただし、Savepointはあくまでrollback用なので注意
- savepointでcommitしても、上位のトランザクションでrollbackされるとsavepointもrollbackする
| |
SavePointのPythonでの例
- 以下はSQLAlchemyでの例
- 注意点としてはネストされたトランザクションを部分コミットできない
- そのため、形式上はネストされたトランザクションをコミットしているように見えるが実際は違う
- 親のトランザクションがロールバックすると子のコミット(に見えるもの)はロールバックする
| |
- これを解決するには新たにトランザクションを切るしかない
- 結局サブトランザクションの内容をコミットするには、コミットしてトランザクションを新規に作る必要がある
- つまり、beginの時にcommitされる
| |
排他ロックと共有ロック
select for updateとselect for shareの違い
- SELECT FOR UPDATE(排他ロック)
- 排他ロック(他のトランザクションは読み取りや更新ができない)が目的
- 用途は、読み取った後すぐにその行を更新する場合
- SELECT FOR SHARE(共有ロック)
- 共有ロック(他のトランザクションはSELECT FOR UPDATEでロックできないが、読み取りは可能)が目的
- 用途は、読み取り専用だが、他のトランザクションがその行を更新するのを防ぎたい場合
select for updateの用途
- 一つの例としては、銀行口座の更新
- 他のトランザクションは読み込みはできるが変更はできなくなる
| |
select for shareの用途
- 例えば、複数のユーザーが同時にレポートを生成する場合
- それぞれのユーザーが読み取るデータが一貫していることを保証する必要がある
| |
- つまり、頻繁に変わるデータがあり、かつ複数人があるタイミングで同時に処理する必要があり、
- その時にその複数人で同じデータを参照したいときに、select for shareを使ってロックする用途
楽観ロックと悲観ロック
- データベースにおける同時実行制御のためのロック戦略
- これらのロックは複数のトランザクションが同時に同じデータを操作する際のデータ整合性を保つために使用する
楽観ロック
- 楽観ロックは、データの競合が発生しないことを前提としたロック戦略。
- トランザクションがデータを読み取り、変更を加えてコミットする際に競合が発生していないかを確認する
特徴
- 競合の前提
- データの競合が稀であると仮定する
- ロックの方法
- データをロックせずに読み取り、更新時にデータの整合性をチェックする
- 適用シナリオ
- 読み取りが多く、書き込みが少ないシステムに適している
| |
もしくは、SELECT ROW_COUNT();を使用してもいいかもしれない。
悲観ロック
- 悲観ロックは、データの競合が発生することを前提としたロック戦略
- トランザクションがデータを読み取る際にロックを取得し、他のトランザクションが同じデータにアクセスできないようにする
特徴
- 競合の前提
- データの競合が頻繁に発生すると仮定
- ロックの方法
- データを読み取る際にロックを取得し、トランザクションが終了するまでロックを保持する
- 適用シナリオ
- 書き込みが多く、競合が頻繁に発生するシステムに適している
| |
ロック
テーブルロック
- RDBのテーブルのスキーマのマイグレーション時に特に使う処理
| |
行ロック
- これは
WAITINGのステータスを持つレコードをロックしている - そのため、例えば、もっと具体的なモノがあればそれでロックするのがベター
- 行ロックはさらに、排他ロックと共有ロックに分かれる
| |
ネクストキーロック
- ネクストキーロックは行ロックとギャップロックの組み合わせ
- いわゆるselect for updateみたいなモノ
$$ ネクストキーロック = 行ロック(レコードロック)+ ギャップロック $$
- Serializableトランザクション分離レベルでの一貫性を保てる
- つまり、ファントムリードを防ぐ事ができる
ギャップロック
- 名前の通りギャップに対してロックをする事
例:
価格が100から200の範囲にある行に対してギャップロックが取得され、この範囲内に新しい行が挿入されるのを防ぐ。
| |
排他処理
排他処理のコツ
- 排他処理をする場合は状態遷移図を先に書いた方がベター
- 排他処理をする前のステータスでロックとWhere句をかけて処理をする形になる
| Current State | Next State | Condition |
|---|---|---|
| WAITING | IN_PROGRESS | Analysis started |
| IN_PROGRESS | FAILED | Error occurred |
| IN_PROGRESS | DONE | Successfully completed |
| FAILED | WAITING | Retry after failure |
- また、関連するレコードも変えたい場合はそれらもその間に取得する必要がある
- 全く同じ処理で別インスタンス、プロセス、スレッド、コルーチンなどからアクセスされる場合は同じ
- また、IN_PROGRESSだからRDBの別のレコードを変更する場合、基本的に同じトランザクションの中でやらないといけない
- ただし、ロックしているトランザクションのスコープが長くなるとよくないので、別の同じような処理をしている所でもロックする必要がある
排他制御の処理方法
- 次のようにトランザクションの中で処理する
- 前提条件をWhere句にする事で状態遷移を確定する
- select for updateで他のプロセスから読み込ませないようにする
| |
競合状態の回避方法
次のような処理が同時に走るとデッドロックになる。
- あるトランザクションで、Aをロック -> Bをロックする順番で、
- 別のトランザクションで、Bをロック -> Aをロックのが同時に走る
その解消方法は以下。
- ロックの順番を揃える
- ロックの範囲を狭める
- トランザクションを短くする
- ロックのタイムアウトの設定
パフォーマンスチューニング
最適化の理由
- 大規模なサービスだとRDBの性能がボトルネックになることがある
- データベースの効率的な運用、リソースの最適化、スケーラビリティの確保、そして全体的なユーザー体験と直結するから
自動インクリメント
- グローバルな一意性を確保するために自動インクリメントIDを使用することが一般的
- これにより、スケーリング時に各シャードで一意のIDが生成
| |
複数ノードでIDのコンフリクトが置きそうな気もするが、シャード事に設定を変えて避ける事が可能。
| |
- UUIDv4だと分散システムにも耐えられるのでOK
- UUIDv3だと別マシンでコリジョンが起きる可能性があるので注意
- ソートもできるUUIDv7が今後は主流になるかもしれない
あえてFKをつけない
- 高トラフィックのアプリケーションで見た設計手法
- テーブルの外部キーに対して、あえてFKをつけずに定義する
- パフォーマンスとスケーラビリティを担保するために制約を極力使わない戦略
理由
パフォーマンス
- オーバーヘッド
- 外部キー制約により、データベースは参照整合性を確保する必要がありオーバーヘッドになる
- 同時実行数
- FK制約は挿入および更新によるロックが増加し、同時実行数が減少する
- オーバーヘッド
スケーラビリティ
- シャーディングの問題
- シャードまたはノード間で外部キー制約を維持することは複雑で非効率的になる
- レプリケーションラグ
- 外部キー制約によりレプリケーション処理が複雑になり、レプリケーションラグが発生
- シャーディングの問題
フレキシビリティ
- 整合性
- アプリケーションレベルでのFKデータ整合性が取れるため
- スキーマ変更
- 外部キー制約により、スキーマの移行がより複雑になる
- 整合性
つまり、アプリケーションレベルでのデータ整合性の担保するという方法
一番深刻なのが、同時実行デッドロックの問題、高負荷なアプリではこれが問題になる
さらにサブデータベスにはFK自体が貼れない問題もある
インデックスの設計
- 適切なインデックスの設計: クエリパフォーマンスを向上させるために、適切なインデックスを設定
- 特に、頻繁に検索されるカラムやジョインに使用されるカラムにはインデックスを設定
| |
次のカラムなどにつける。
- 頻繁に検索されるカラム
- ジョインに使用されるカラム
- 一意性を保証する場合(UNIQUEインデックス)
シャーディング戦略
- Vitessを基盤とすることでmysqlでシャーディングをサポートできる
- シャーディングキー(dynamodbでいうpatitionkey)の選定が大切
- データを均等に分散させ、負荷分散をする事が目的のため
| |
リードレプリカの活用
- 主に読み取り専用のクエリを処理する目的で使用されるデータベースのコピーの事
- 例
- Staticな製品カタログの閲覧や検索クエリをリードレプリカにオフロードする
- ダイナミックメインデータベースは注文処理や在庫管理などの書き込みトランザクションに集中させる
- CDNとAPIの違いみたいなモノ
クエリ最適化
- EXPLAINとEXPLAIN ANALYZE、ANALYZEを使ってクエリの実行計画を取得する
- ここら辺のチューニングは深いので、別ページにする
水平スケール vs. 垂直スケール
RDBによる、例えば、次のような違いがRDBによってある。
- PostgreSQLは、垂直スケーリング(スケールアップ)型
- CockroachDBは、水平スケーリング(スケールアウト)型
分散システム
分散ロック
分散ロックとは
- 分散ロックは、複数のプロセスやノードが同時にリソースにアクセスするのを制御するためのメカニズム
- 分散システムにおいてデータの整合性と一貫性を維持するため使用する
- 有名なのはRedisやApache Zookeeperによる分散ロック
RDBを使ったロック
- 一番シンプルなのがRDBを使ったロック
- あるリソースに対して使用中のロックのフラグを立てる
- CONFLICT DO NOTHINGはINSERT文を実行する際に、挿入しようとするデータが既に存在する場合に何も行わないようにするためのもの
テーブルの定義
| |
分散ロックの例
| |
Redisを使った分散ロック
- RedisのSETNX(Set if Not Exists)コマンドを使用して分散ロックを実現できる
- SETNXコマンドは、キーが存在しない場合にのみセットするため、ロックの取得が競合しない
| |
分散トランザクション
分散トランザクションとは
- 分散トランザクションは、複数のネットワーク上にある独立したデータベースやシステムに対して、一貫性を保ちながらトランザクションを実行するためのプロセス
- 複数のデータベースにまたがってアトミックに処理しなければならない時などに必要となる
分散トランザクションのパターン
分散トランザクションは、大体以下の2つのプロトコルによって実現する。
- 2フェーズコミットプロトコル(2PC: Two-Phase Commit Protocol)
- フェーズ1: 準備(Prepare):
- トランザクションコーディネータは、すべての参加者に対してトランザクションの準備を依頼
- 参加者はローカルトランザクションを準備し、成功したかどうかをコーディネータに通知
- フェーズ2: コミット(Commit):
- すべての参加者が準備完了を通知すると、コーディネータはコミットを指示
- コーディネータがコミットを指示すると、すべての参加者はトランザクションをコミットし、完了を通知
- もし一つでも準備に失敗した場合、コーディネータはすべての参加者にロールバックを指示
- フェーズ1: 準備(Prepare):
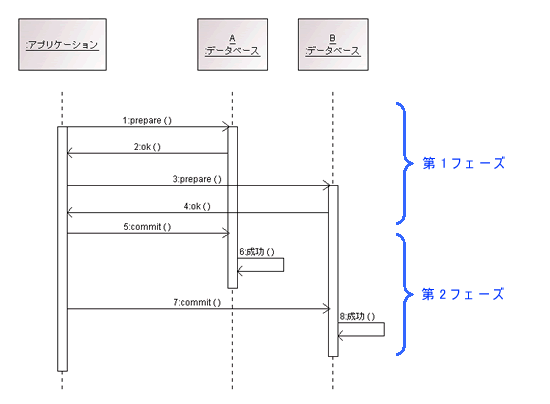
- 3フェーズコミットプロトコル(3PC: Three-Phase Commit Protocol)
- 2PCのデッドロック問題を回避するために、3PCではさらに準備段階を追加して、参加者がコミットする準備ができるかどうかを確認
- これにより、ネットワーク分断などの障害が発生した場合にデッドロックを回避することができる
分散トランザクションの例
- SpringとAtomikosを使った例
Atomikos Transaction Manager
| |
使用例
| |
その他
UNIQUE_KEYへのNull
ユニークキーへの2つ以上のnullの挿入では次の違いがある。
- postgres: OK
- mysql: duplicated
入れるべきモノは最初に入れるべき
- 基本的に制約は消すのは簡単だが後から追加するのは大変
- 例えば、新たにFKの追加や、UKの追加など
- また、データは本来正規化後に決定されるモノ
- 故に、今は使わなくても入れるべきリレーションや制約は最初に追加するべき
- 後々データマイグレーションをすると大変になる
重複したデータ
- 基本的にマスターテーブル以外でも重複したデータは入れるべきではない
- 何かしらのカラムで本来はユニークできるはずだから
- 不用意に完全に重複したレコードがある場合は設計ミス
N+1クエリ
- N+1クエリ問題は、データベースアクセスにおけるパフォーマンス上のアンチパターン
- ORMではEager LoadingやPrefetchなどで無駄なクエリが走らないように注意する
owner_idパターン
- あえてレコード全てに所有者のuser_idをFKとして持たせる手法
- owner_idとして必ずそれらをチェックする事でデータの権限の整合性を保つ
- ただしパフォーマンスは良くない
JOINやサブクエリを発行しない
- JOINやSub queryもパフォーマンスの問題にあたるのでパフォーマンスが余裕な時を除いて行わない
- するならWITH句のCTE(Common Table Expression)式を使ってあらかじめ計算する
例
| |
あらかじめCTEで過去一年間分を別途計算しJOINする。
| |
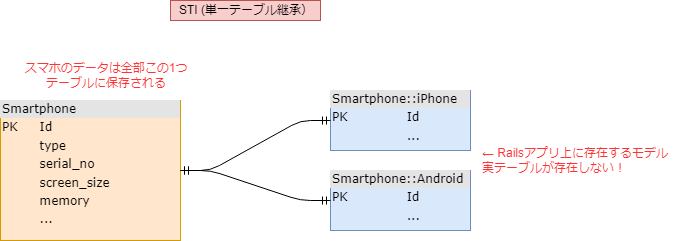
STI(Single Table Inheritance)
- STIはRailsで行うテーブル設計のパターン
- OOPの継承に似ているが実態は、タグ付きUnion型に近いイメージ
| |
- 下の図では、androidとiphoneというテーブルは存在せず、一つのphoneというテーブルで管理される
- その際にsmartphoneテーブルのtypeによってアプリケーション側で必要なカラムのみを出す仕組みとなる
- 完全な親子関係(is-a)があるテーブル同士をDIYにまとめる手法
発番テーブル
次のフローで裁判テーブルを更新する。
- トランザクション開始
- 採番テーブルからレコードを取得してロックする
- noを+1してレコードを更新する
- トランザクションをコミット(ロックが解除される)
| |
実行は次のSQLでロックする。
| |
- もしくは、IDの設計をして、Prefix+BigIntとするのが良い
- 単なるBigIntだとFKエラーも抜けてしまうため
過去の値を元にロックする手法
- 下の商品の在庫の個数を減らすコードは同時実行されると、
- トランザクションの分離レベルによるが、破綻する可能性があるので注意
| |
- 上の在庫管理はクリティカルなビジネスプロセスなので、ロックするべき
- つまり、下のようになる
| |
- ただし、簡易的な排他処理、例えばブログの投稿のrevision管理などでは、
- パフォーマンス重視でわざわざ行ロックをしなくてもいい気もする
| |
辞書テーブル
本質的にアプリケーションの設定は2種類ある。
- Static setings
- コードレベルで決まっている設定値
- Dynamic settings
- ユーザーレベルで決まっている設定値
このうち、StaticはYamlでもコードでもいいが、DynamicはDBに落す必要がある。
(なぜなら、そうしないとユーザードリブンで変えられないから)
上のような形でテーブルを定義し、seedやfixtureという形でmasterデータを投入する。
もしdict_typeにメタ情報を付与したいなら、別テーブルにしてもいいかもしれない。
| |
接続テスト
接続テキストには軽量クエリを使ってチェックすることが多い。
| |
参考文献
- Rails Single Table Inheritance and DRY Code (日本語) | Chien Kira
- 採番処理と排他制御 | 社員ブログ | リグレックス株式会社 | REGREX Co.,Ltd.
- WHERE 条件のフィールドを UPDATE するのって,明示的にロックしてなくても安全?全パターン調べてみました! #MySQL - Qiita
- P of EAA
- Operating without foreign key constraints — PlanetScale Documentation
- 18 SQL Join Techniques Explained. Mastering SQL Joins: The Ultimate Guide… | by 🐼 panData | Level Up Coding
- best way to create a savepoint in sqlalchemy - Stack Overflow
- トランザクションの分離
- パフォーマンスチューニング9つの技 ~「探し」について~|PostgreSQLインサイド : 富士通
- 分散トランザクションに挑戦しよう!
- マリコ、もがく。―整合性に歴史あり― – QUICK GUARD スタッフブログ
- What is Snapshot Isolation? - GeeksforGeeks
- PostgreSQL で私たちが最も嫌う部分 // ブログ // Andy Pavlo - カーネギーメロン大学
- トランザクションデータを要約する技術「マークルツリー」
- データベースの正規化(第1〜第3正規形) - Wiz テックブログ
- INDEX(インデックス)のメカニズム – データベース研究室
- A discussion of SQL foreign keys.