目次
概要
- TransformerはGPTやBERTにも使用されるNLPのモデルのアーキテクチャ
- TransformerはAttention / Self-Attention機構やスケーラビリティが特徴的
- ただ今回は、TokenのPositional Encodingについての解釈メモ
- ある程度Transformerの知識がある前提でPositional Encodingについて説明する
NOTE:
- 便宜上形式的に単語=tokenの同義としている
- サブワードなどの処理については説明は行わない
Transformer
そもそもTransformerとは
ざっくり言うと次となる。
- 2017年にGoogleの研究者によって紹介されたアーキテクチャ
- Transformerは、NLPの分野で使用される
- 多くのNLPタスクで卓越した性能を示す
Positional Encodingの場所
先にTransformerの全体図とPositional Encodingの場所を示す。
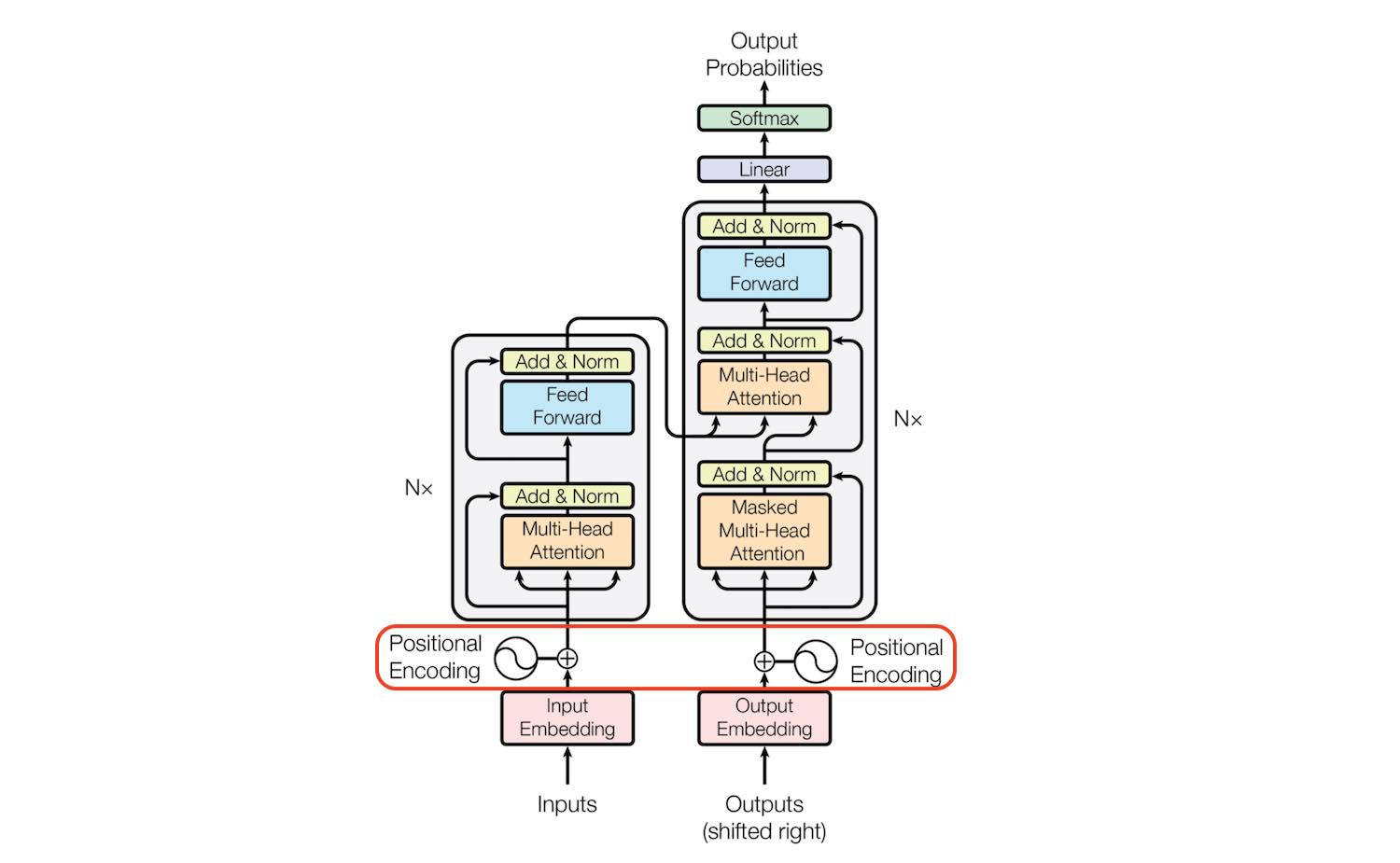
- 全体でみると、Positional Encodingは、Attention機構(図中のMulti-Head Attention)の前に、Inputを加工するために行われる
- 図中の太陽十字はelement wise sumを意味し、tokenのembeddingのベクトルとPositional Encodingのベクトルを加算することを意味する
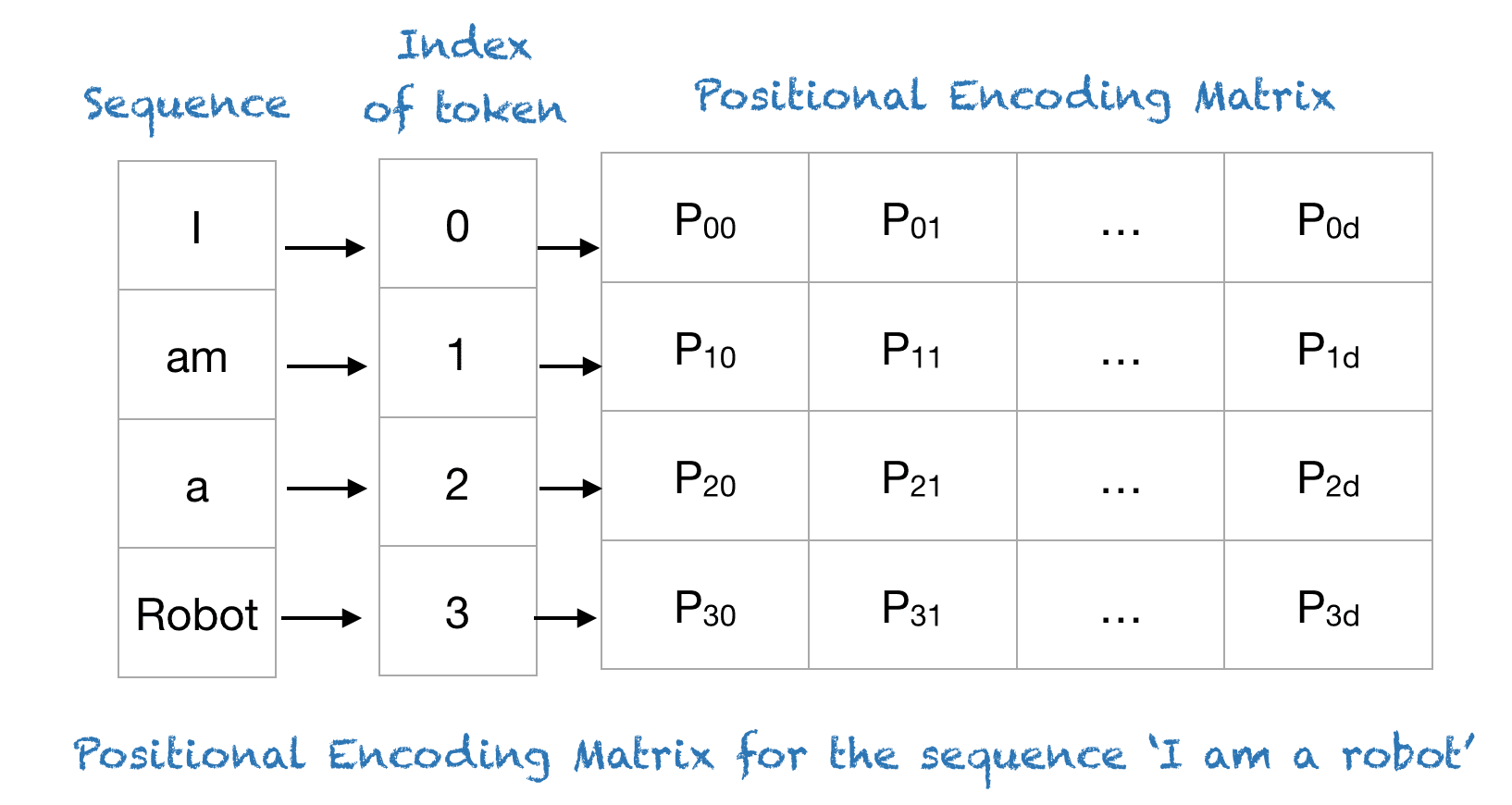
そもそもPositional Encodingとは何か
- 下図にPositional Encodingとtokenの関係を示す
- 文字(token)はi am a robotだが、そのtoken毎にpositional encodingとしてベクトルがある
- このベクトルがPositional Encoding
- なお、図中の$d$はtokenの埋め込みの次元数を意味している
このように、Positional Encodingはtokenの埋め込み次元分作成し、tokenの埋め込みベクトルに対して加算することで、positionをtokenに加算し、表現する仕組みである。
Transformer全体で見たときの意味
では、Transformer全体で見たときの、Positional Encodingの意味とは何か?
- もちろん、tokenの文中の位置である
- ただ、なぜ位置が重要かと言うと、実はTransformerのコアであるAttention機構では位置を考慮しないからである
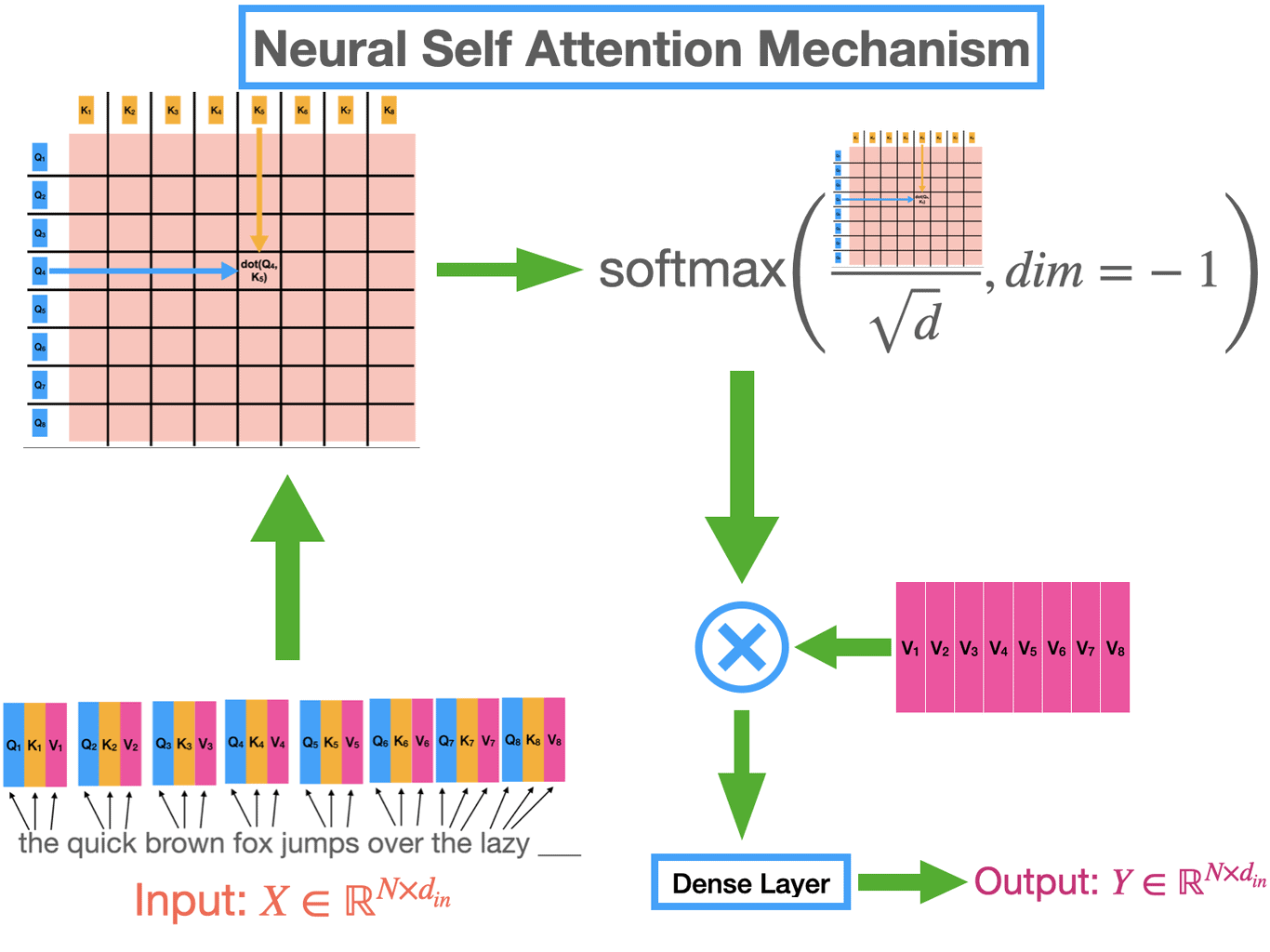
Attention機構の概略
下図にAttention機構の概略を示す。
- シンプルに図解すると、下図のような処理をattention機構では行っている
- あくまでトークンとトークンの関係のみを考慮して、どのトークンに注目するのかを決定している
- 故に、attention機構だけでは文字の場所を考慮していない仕組みとなっている
Attentionの前に使われていた機構
Attentionが流行る前はRNNやLSTMがNLPのデファクトスタンダードだった。
- 例えば、Transformerの前に使われていたRNNやLSTMでは、Positional Encodingが不要だった
- なぜなら、入力シーケンスを順序通りに処理し、各時点での隠れ層で時系列を考慮できたから
- つまり、RNNなどでは、時系列データの文脈を隠れ層で捉えていた
- 他方、TransformerはAttentionを使うが、Attentionはシーケンスを考慮しない
- 故に、Positional Encodingが重要になってくる
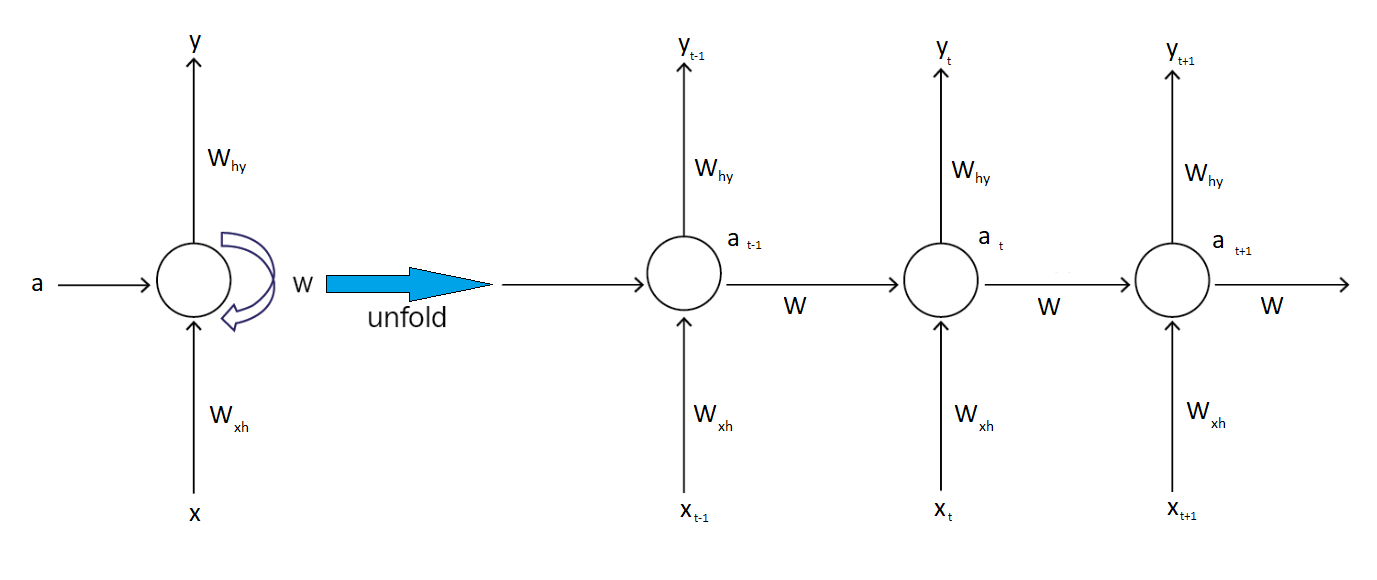
上図にRNNのメカニズムを示す。
ちなみに、ここで、各文字列は次を示す。
- $W_{xh}$: input(x)から隠れ層への重み
- $W$: 隠れ層から隠れ層への重み
- $W_{hy}$: 隠れ層からoutput(y)への重み
- $a$: アクティベーションレイヤー
Positional Encodingの詳解
単語のベクトル表現
単語のベクトル表現方法
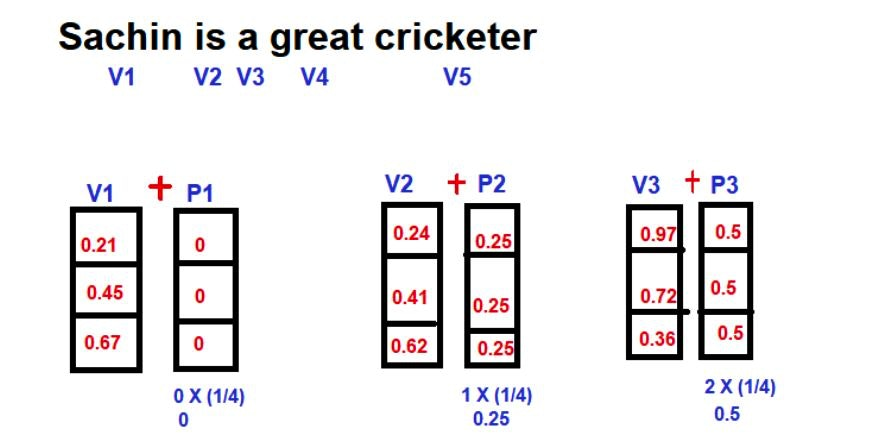
まず、Positional Encodingを加算される前の、単語のembeddingを次に示す。
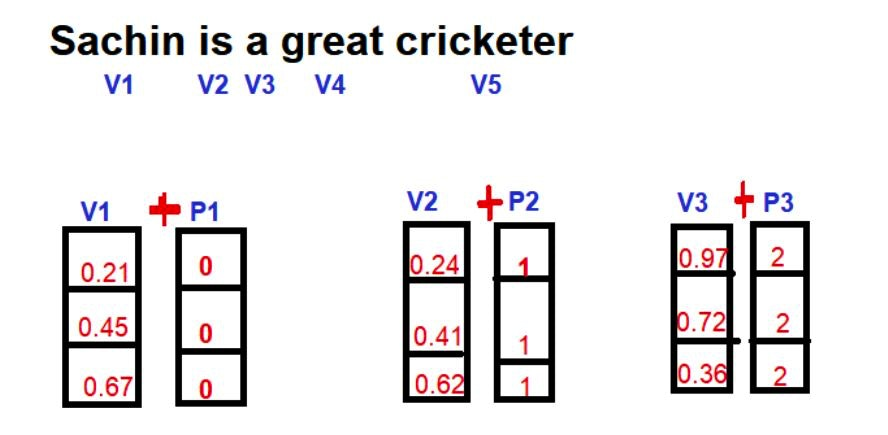
上図の通り、単語に対して、3次元の埋め込み空間を用意し、単語のembedding表現をしている。
Vは単語の埋め込みベクトル、Pは単語のPositional Encodingである。
単語のベクトル表現への位置の追加
そして、それを単語のベクトル空間に落とすと次のようなイメージになる。
赤、青、緑の線分が単語のベクトル表現を示す。
これに対して、Positional Encodingを加算しているのが、緑の線分である。
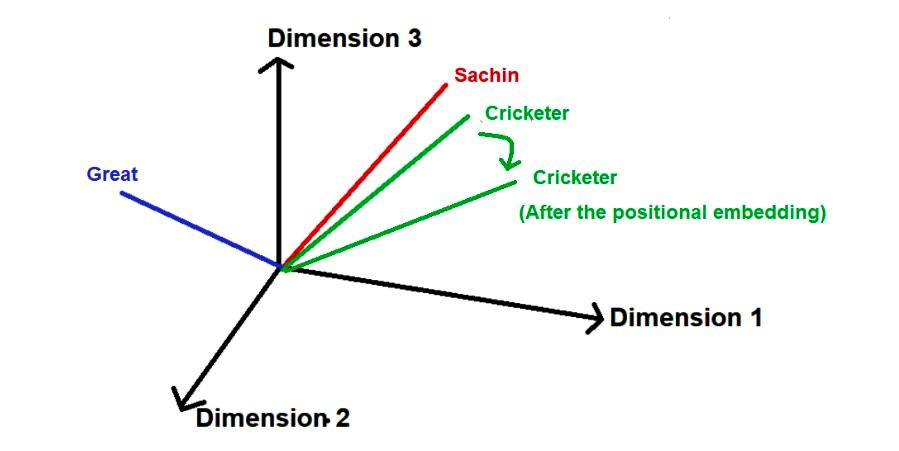
- つまり、単語空間に対して位置を加算する事によって、位置情報も付与するという事である
- 緑のベクトルはPositional Encodingを加算後にベクトルの向きが変わっている
これがシンプルに言う、tokenへのPositional Encodingの追加と言う事。
ポジションの値の決め方
位置を値にする
では、何をPositional Encodingの値とするのか?
最もシンプルなのは、下図のようにtokenのpositionを埋め込む事。
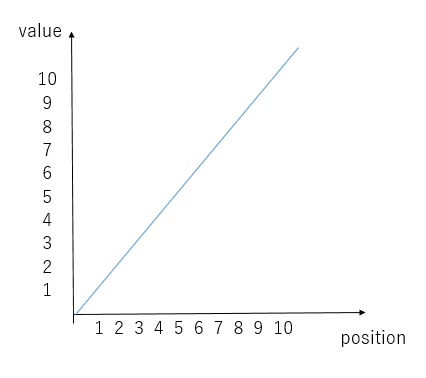
100 token目のPositional Encodingの値は100になると言う事。
値域を制限して位置を値にする
- ただ、上の方法は、文が長いと際限なく値が大きくなる
- つまり、元々のtokenの埋め込みに大きすぎる影響を与えてしまう事を意味する
- そうすると、元々のtokenの埋め込みの意味がつぶれてしまう
そこで、次のように抑制する。
ここで、$pos$はtokenの位置を示す。
$$ \text{position value} = \frac{1}{pos−1} $$
- 例えば、位置が100 token目だった場合は$\frac{1}{99}$となる
- この手法では、文の長さに関係なく、Positional Encodingの最大値を1に制限できる
例:
- 4個のtokenを持つ文の1つ目のtokenのposition値
- 1/3 = 0.33
- 10個のtokenを持つ文の1つ目のtokenのposition値
- 1/9 = 0.11
上図は5 tokenある文の、それぞれに、一定のPositional Encodingの値を付与している。
sin関数で埋め込む方法
ただ、上の手法でも次の問題があった。
- テキスト、コーパス全体で同じ埋め込み値を持つ必要がある
- また、表現が豊かではない事、関数のsmoothさなど
そこで、周波数ベースの位置埋め込みが発案された。
- なお、三角関数の他には
[0, 1]を取るsigmoidなどがあるが、端に行くほど変化が鈍化してしまう欠点があった - その点三角関数はpositionが大きくなってもvalueを変化させられて表現が豊かである
周波数を考慮してsin関数で埋め込む方法
しかし、上記の方法は、次の問題があった。
- 周期関数なので、positionが変化しても同じvalueの値が返される
- これは近傍のトークン間の違いは表せても遠くのトークンの違いを表現できない
そこで最大の文章量が来てもvalueが繰り返されないほど低い周波数も与えた。
- これで長い文章が来ても位置情報を個別に割り振れた
- つまり、低周波は近くのtokenとの関係を、高周波は遠くのtokenの関係を表現できると言う事
sinとcosを組み合わせて周波数を考慮して埋め込む方法
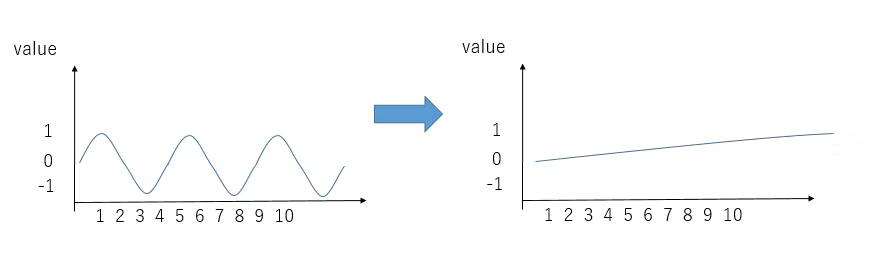
ただ上記の方法でも、次の問題があった。
- なぜなら低周波数にしたため、positionが小さいとき(例えば1, 2の場合)値がほとんど変化しない
- イメージは下の図の感じである
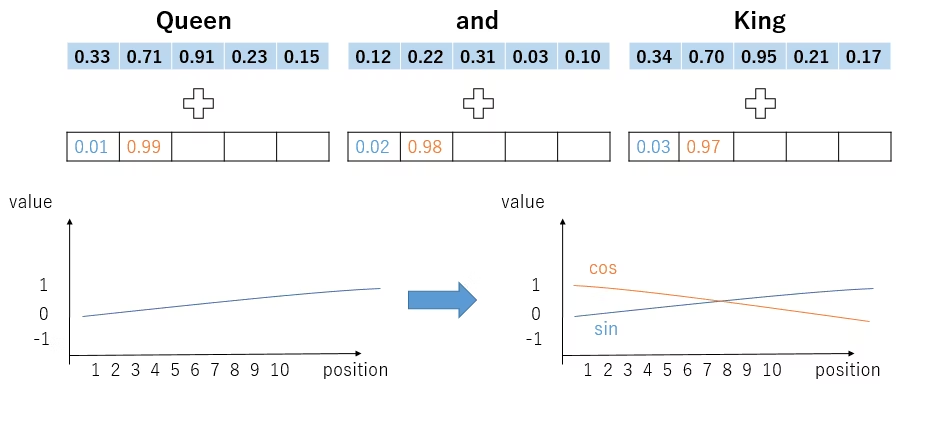
- 故に、90度ずれるsinとcosを組み合わせて利用する
最終的な要件
つまり、表現の豊かさ、値域の制限、スケーラビリティなどを考慮して、最低必要なのは次の要素だった。
- トークンのpositionに応じて変化させる
- sin / cosを組み合わせて位置を埋め込む
- 低周波と高周波を組み合わせて、近傍と遠くの関係を表現する
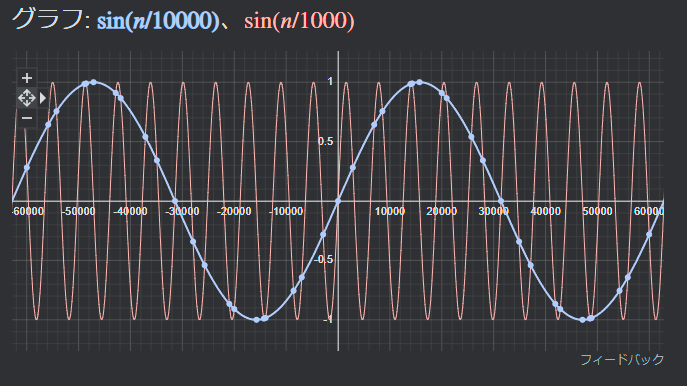
Position encodingの数式
結果、それらをまとめると次になる。
$$ {PE\left( pos,2i\right) =\sin \left( \dfrac{pos}{10000^{2i/d_{model}}}\right) } $$
$$ {PE\left( pos,2i+1\right) =\cos \left( \dfrac{pos}{10000^{2i/d_{model}}}\right) } $$
ここで変数は次を示す。
- 「pos」は、文中の特定のtokenの位置
- 「d」は、文中の特定のtokenを表すベクトルの最大長/次元
- 「i」は、各位置埋め込み次元のインデックス
また、2i+1の意味は次である。
- 偶数番目(2n)の場合はsinを、奇数番目(2n+1)の場合はcosの関数を利用する
また、PEとtokenの埋め込みベクトルの関係を示すと次のようになる。
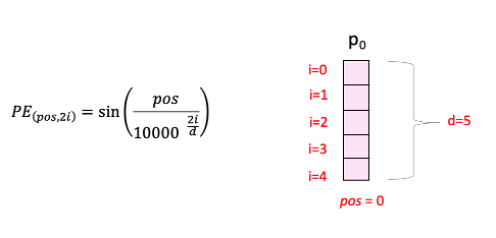
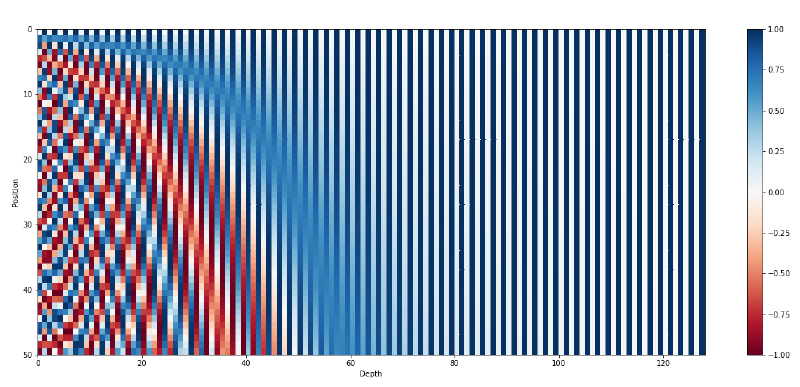
Positional Encodingの可視化
それを可視化すると次になる。
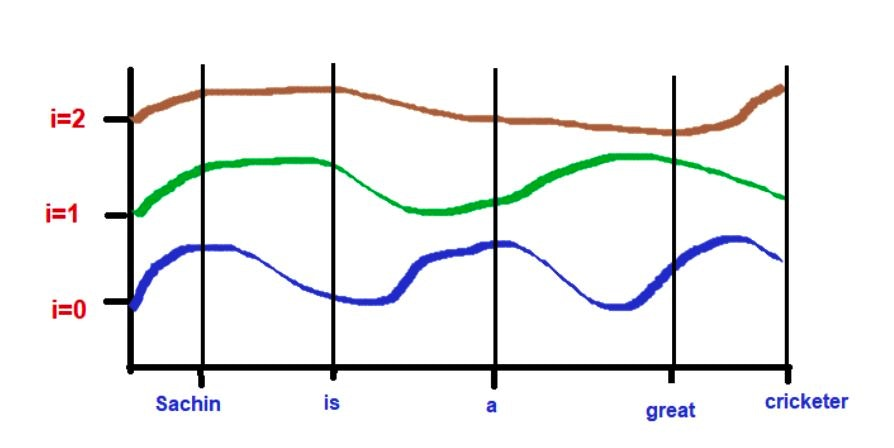
つまり上図から次が言える。
- 次元のindexが低いほど、高周波
- 次元のindexが高いほど、低周波
position=3の場合の計算の例。
- i=0 の場合
- PE(3,0) = sin(3/10000^2(0)/3)
- PE(3,0) = sin(3/1)
- PE(3,0) = 0.14
- i=1 の場合
- PE(3,1) = cos(3/10000^2(1)/3)
- PE(3,1) = cos(3/436)
- PE(3,1) = 0.99
- i=2 の場合
- PE(3,2) = sin(3/10000^2(2)/3)
- PE(3,2) = sin(3/1.4)
- PE(3,2) = 0.03
tokenの埋め込みベクトルと位置埋め込みの関係を次に示す。
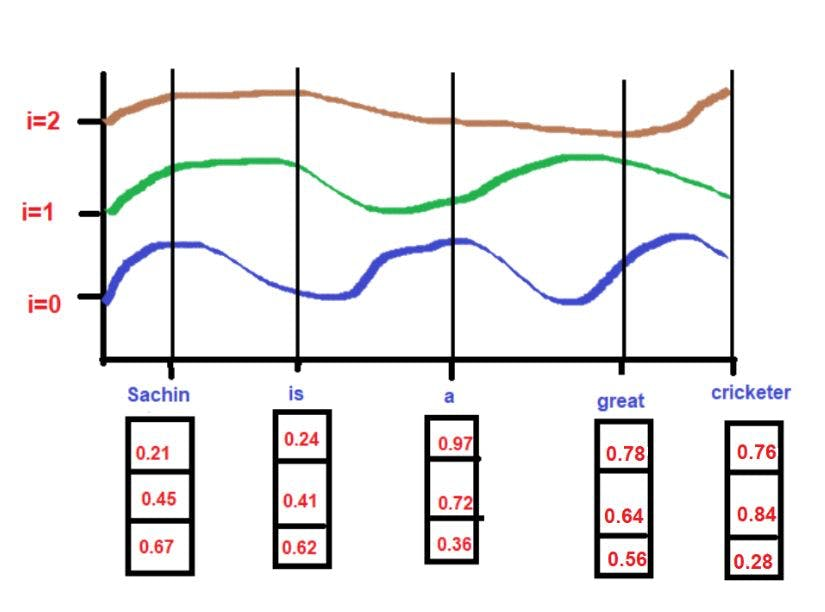
- 下図のように、tokenのembeddingのi番目の値が周波数のi番目によって加算される
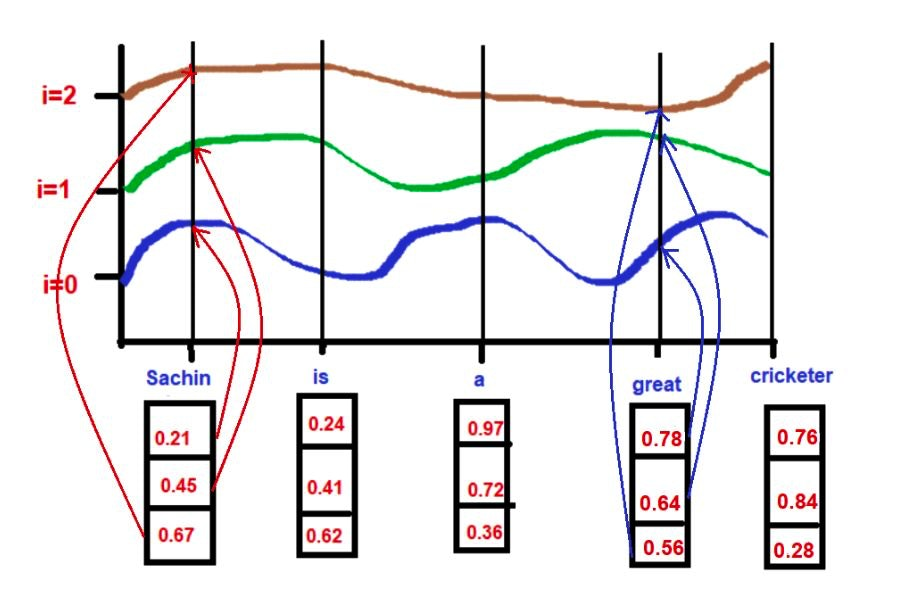
つまり次が言える。
- 高周波(i=0)の時はpositionのlocal featureが表れる
- なぜなら周期が早いので、近くのtoken間の差が大きく出るから
- 低周波(i=2)の時はpositionのglobal featureが表れる
- なぜなら振幅が遅いので、全体的に差が出るように周期するから
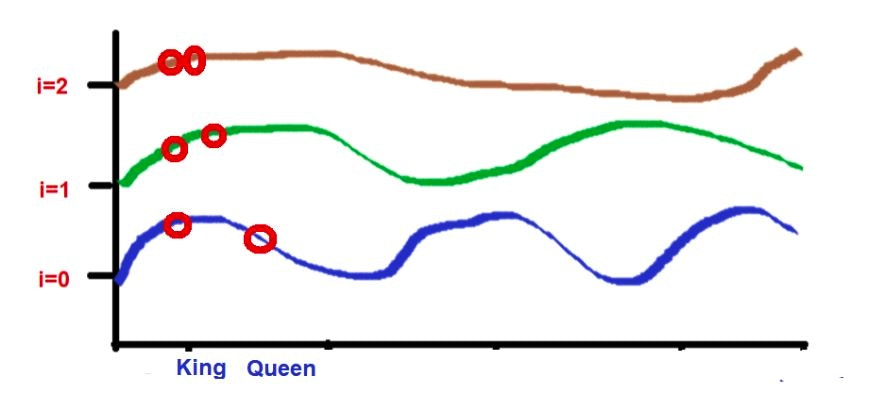
- つまり、別の言い方をすると、位置情報を全体と部分の振幅をもつ周波数に分解してそれぞれの埋め込み次元に適用している
- これは、おそらく周波数の合成をできるフーリエ変換をバラして適用している感じと捉えられる
- つまり、高周波と低周波をミックスすると、位置ごとに別々の表現にちゃんとなっているだろうということ
Positional Encodingの可視化
positionとdimensionとsin/cosの等高線
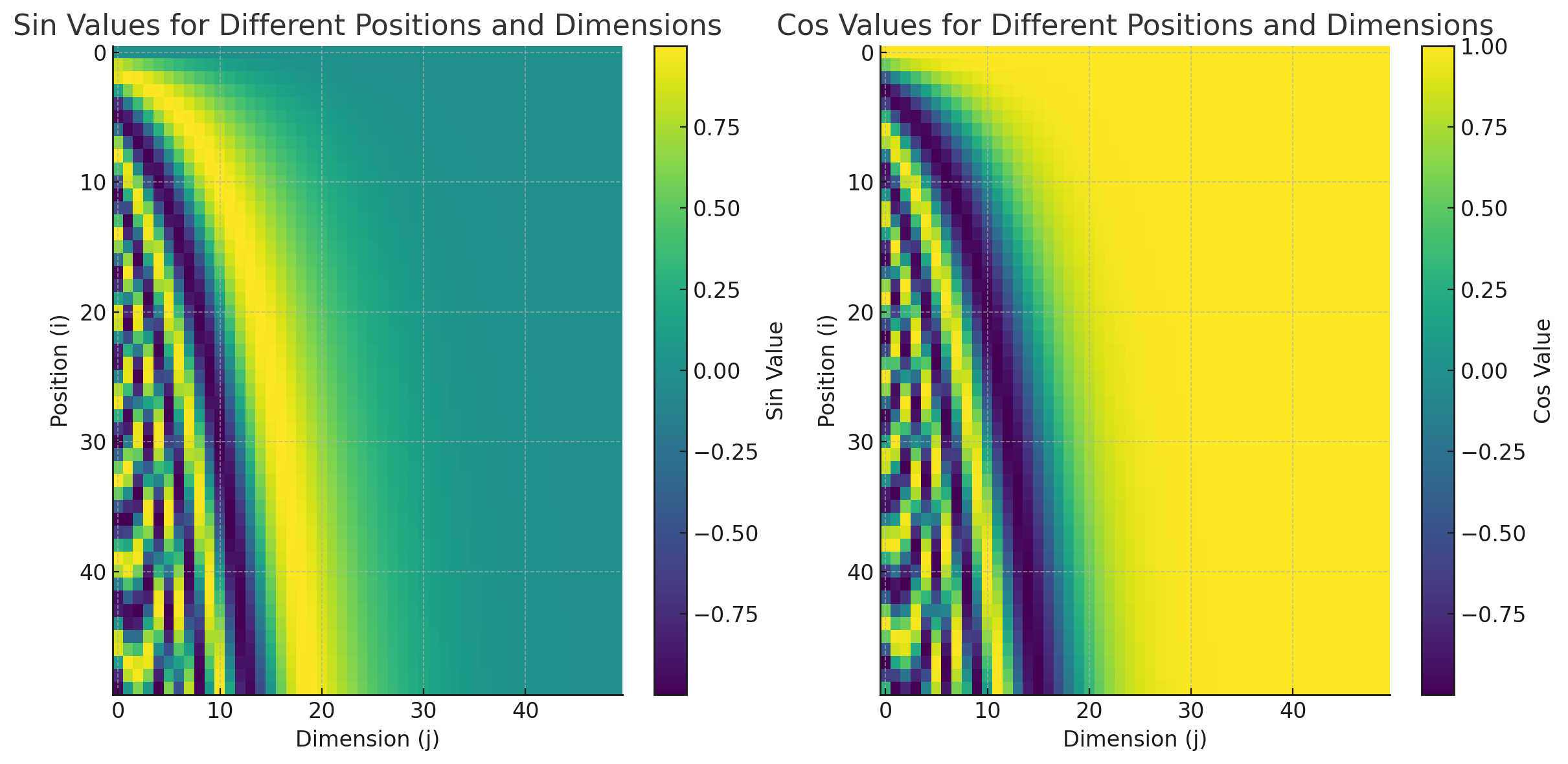
次にpositionとdimensionとsin/cosの等高線を示す。
- dimensionが低いと(encoding vectorの最初の方のindexの要素)は、高周波で、要素の番数が大きくなるほど、低周波になる
- これは、低次元と高次元を表現できることを意味する。なお、20番目以降ぐらいからは収束する
encodingが取りうる値
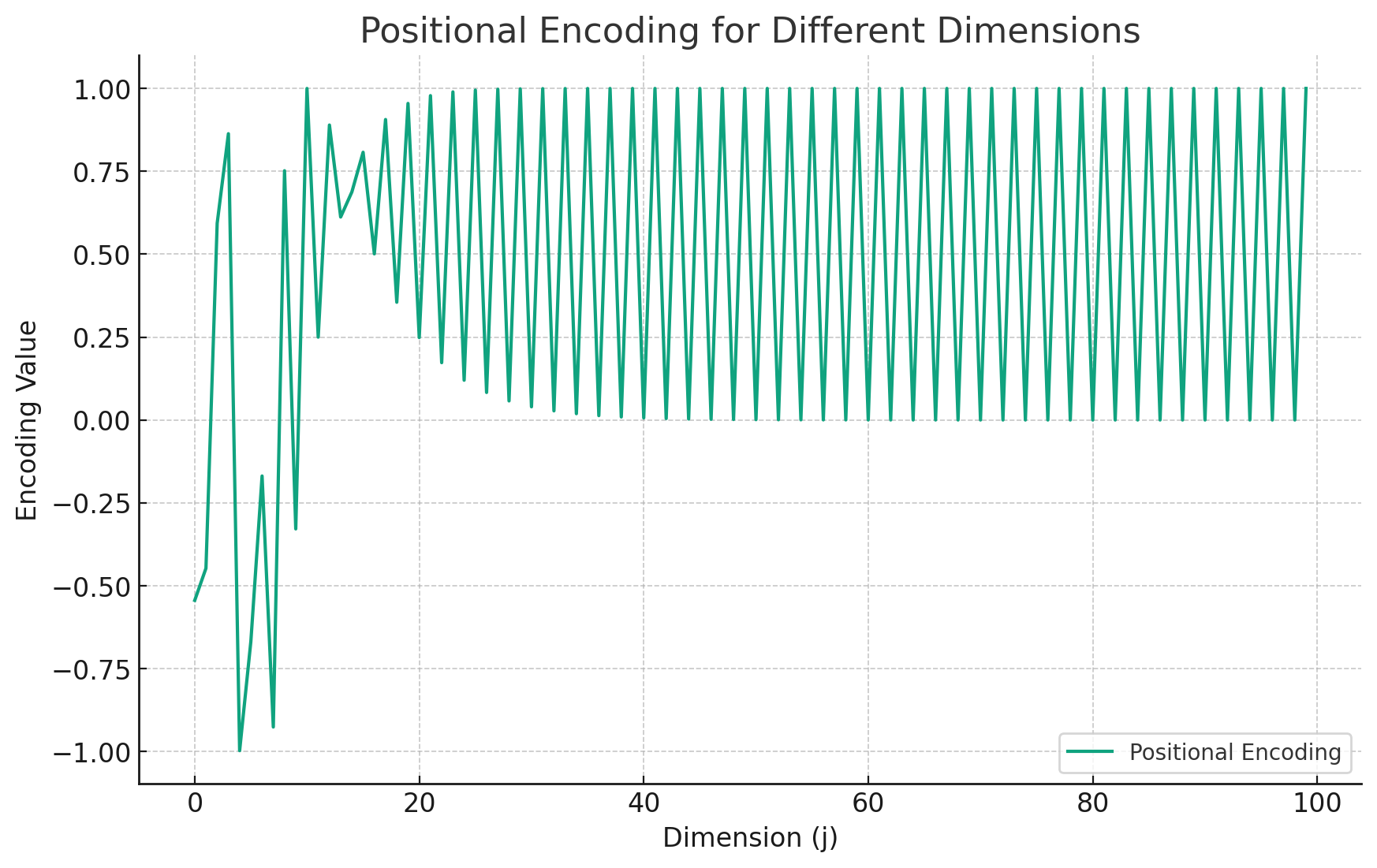
次にencodingが取りうる値を2次元にして示す。
- pos=10での位置埋め込みの値、横軸は埋め込みベクトルの次元jを表し、縦軸は位置埋め込みの値を示している
- jが縦に入れ替わっているのは、cos/sinの入れ替わりがあるから
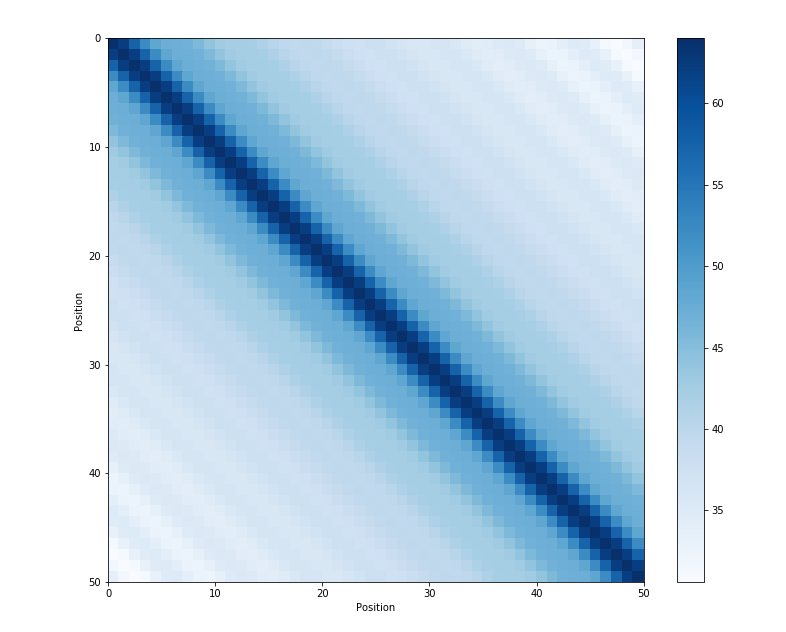
高周波と低周波の組み合わせの可視化
位置埋め込みで内積を取ったグラフを示す。
- 同位相の波は強く干渉している
その他
EncodingとEmbeddingとは
EncodingとEmbeddingを説明する。
- Encodingは変数のベクトル表現のこと
- 例えば、リンゴ、オレンジ、チンパンジーを表現するとする
one-hot encodingで、バイナリで表現する方法は次となる。
- リンゴ:
[0, 1, 0] - オレンジ:
[0, 1, 0] - チンパンジー:
[0, 0, 1]
つまり、1次元目がリンゴ、2次元目がオレンジ、3次元目がチンパンジーのbitと言う事である。
ただし、これらの内積をとっても、類似性を考慮できない。
- 理由は内積が全て0になるからである
明らかにリンゴとオレンジは意味が近く、リンゴとチンパンジーはそれと比較して意味が遠い。
そこでtokenの埋め込み(Embedding)を行う。
- リンゴ:
[0.1, 0,9, 0.1] - オレンジ:
[0.2, 0,9, 0.1] - チンパンジー:
[-0.9, 0,4, -0.9]
すると、cos類似度などで近似性をとれる。
リンゴとオレンジは1に違い値となるが、リンゴとチンパンジーは-1に近い値となる。
- 単純に言うと、これがembedding
- つまり、embeddingとは、高次元(上述の例では3次元)に意味埋め込むという事
- 内積やcos類似度は埋め込み空間でのベクトルの向きの一致度(ベクトルの類似度)を示している
EncodingとEmbeddingの違い
埋め込みや表現では境界線が曖昧だが、両者には明確な違いがある。
- encodingは符号化
- embeddingは埋め込み
また、Trainingの視点だと次の違いがある。
- Encodingは学習しない(つまり、static)
- Embeddingは学習する(つまり、dynamic)
なぜ三角関数で上手くPoistional Encodingができるのか
We chose this function because we hypothesized it would allow the model to easily learn to attend by relative positions, since for any fixed offset k, PEpos+k can be represented as a linear function of PEpos.
上が元々の論文での説明。 つまり、固定オフセットの場合、モデルが相対位置による学習を簡単に学習できるという仮説があったと言う事。
実は絶対位置より相対位置(Relative Positioning)の方が重要であり、機械学習は内積の集積なので、線形変換ができる事=学習の容易さを示す。 例えば、I have a pen. だと、絶対的な4番目のpenの位置という情報より、aをoffsetとしたpenの位置が重要。
相対位置で線形変換ができる事の証明
全てのsine-cosine pairの$\omega_k$に対する、以下の式を満たす$M \in \mathbb{R}^{2\times2}$(tからは独立)が存在するという事。
$$ \newcommand{\br}{\\} M\begin{bmatrix} \sin(\omega_k . t) \br \cos(\omega_k . t) \end{bmatrix} = \begin{bmatrix} \sin(\omega_k . (t + \phi)) \br \cos(\omega_k . (t + \phi)) \end{bmatrix} $$
ここで、それぞれ次を意味する。
- $k$ はPositional Encodingのindex(最小は0、最大は$=\frac{d_{model}}{2} $)
- $\phi$はoffset(元々の数式で言うpos)
- $t$は欲しいtokenのoffsetからの相対pos
線形変換されるベクトルは次のように$i$番目のindexから$k$を場合分けで算出する。
$$ \newcommand{\br}{\\} \begin{align} \vec{p_t}^{(i)} = f(t)^{(i)} & := \begin{cases} \sin({\omega_k} . t), & \text{if}\ i = 2k \br \cos({\omega_k} . t), & \text{if}\ i = 2k + 1 \end{cases} \end{align} %]]> $$
Mを$2 \times 2$の行列とし、次の$u_1, v_1, u_2, v_2$を探す。
$$ \newcommand{\br}{\\} \begin{bmatrix} u_1 & v_1 \br u_2 & v_2 \end{bmatrix} \begin{bmatrix} \sin(\omega_k . t) \br \cos(\omega_k . t) \end{bmatrix} = \begin{bmatrix} \sin(\omega_k . (t + \phi)) \br \cos(\omega_k . (t + \phi)) \end{bmatrix} $$
加法定理より、右辺を展開すると次になる。
$$ \newcommand{\br}{\\} \begin{bmatrix} u_1 & v_1 \br u_2 & v_2 \end{bmatrix} .\begin{bmatrix} \sin(\omega_k . t) \br \cos(\omega_k . t) \end{bmatrix} = \begin{bmatrix} \sin(\omega_k . t)\cos(\omega_k .\phi) + \cos(\omega_k . t)\sin(\omega_k .\phi) \br \cos(\omega_k . t)\cos(\omega_k .\phi) - \sin(\omega_k . t)\sin(\omega_k . \phi) \end{bmatrix} $$
その結果、次の方程式が成り立つ。
$$ \newcommand{\br}{\\} \small \begin{align} u_1 \sin(\omega_k . t) + v_1 \cos(\omega_k . t) = & \ \ \ \ \cos(\omega_k .\phi)\sin(\omega_k . t) + \sin(\omega_k .\phi)\cos(\omega_k . t) \br u_2 \sin(\omega_k . t) + v_2 \cos(\omega_k . t) = & - \sin(\omega_k . \phi)\sin(\omega_k . t) + \cos(\omega_k .\phi)\cos(\omega_k . t) \end{align} $$
上を解くと次を得る。
$$ \newcommand{\br}{\\} \begin{align} u_1 = \ \ \ \cos(\omega_k .\phi) & \ \ \ v_1 = \sin(\omega_k .\phi) \br u_2 = - \sin(\omega_k . \phi) & \ \ \ v_2 = \cos(\omega_k .\phi) \end{align} $$
結果、行列の$M$は次となる。
$$ \newcommand{\br}{\\} M_{\phi,k} = \begin{bmatrix} \cos(\omega_k .\phi) & \sin(\omega_k .\phi) \br - \sin(\omega_k . \phi) & \cos(\omega_k .\phi) \end{bmatrix} $$
上のMは$t$に依存しない行列であり、任意のoffset($\phi$)からの$t$番目のtokenのPositional Encodingについて、 $t$なしで、$M_{\phi,k}$の線形変換で得られる事を意味する。つまり、$\vec{p_{t+\phi}}$を$\vec{p_t}$から表現できる事を意味する。 行列の中身はいわゆるCVのローテーションマトリックスとほぼ同じである。 また、ベクトルが2次元では無い時は、対角行列を使えば同じ結果となる。
三角関数の周波数(Frequency)の意味
前述で次のように各tokenのposition encodingを定義したが、三角関数の内部の式の意味を説明する。
$$ \newcommand{\br}{\\} \vec{p}(pos) := \begin{bmatrix} \sin\left(\frac{pos}{f_1}\right) \br \cos\left(\frac{pos}{f_1}\right) \br \sin\left(\frac{pos}{f_2}\right) \br \cos\left(\frac{pos}{f_2}\right) \br \vdots \br \sin\left(\frac{pos}{f_d}\right) \br \cos\left(\frac{pos}{f_d}\right) \br \end{bmatrix} $$
ここで、$f_d$は$f_{\frac{d_\text{model}}{2}}$を示す。 なぜ、$d_{model}$に対して2で割るかと言うと、偶数奇数でsin/cosを使っているので、最大で$\frac{d_{model}}{2}$分のrangeを使うため。
さらに、あるposition番目のtokenではpositionは定数の為、逆数であれば良く、あるi番目のfrequencyは波長$\lambda$を使い、次のように表せる。
$$ f_i = \frac{1}{\lambda_{i}} := 10000 ^ {\frac{2i}{d_{model}}} $$
なお、基数の$10000$はハイパーパラメータとなる。 これがPositional Encodingの数式の意味となる。
参考文献
- Understanding Positional Encoding in Transformers - Blog by Kemal Erdem
- Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad’s Blog
- Positional Encodingを理解したい #DeepLearning - Qiita
- 位置埋め込み: Transformer Neural Networks の精度の背後にある秘密 | HackerNoon
- Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad’s Blog
- 大規模言語モデル入門
- Understanding Attention Mechanism in Transformer Neural Networks
- Introduction to the Architecture of Recurrent Neural Networks (RNNs) | by Manish Nayak | Towards AI
- A Gentle Introduction to Positional Encoding in Transformer Models, Part 1 - MachineLearningMastery.com
- Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad’s Blog
- Linear Relationships in the Transformer’s Positional Encoding - Timo Denk’s Blog
- [1706.03762] Attention Is All You Need
- Trigonometric Functions Formulary - Timo Denk’s Blog