
目次
概要
- 仕事で外国人とやり取りする時に数学用語はよく使う
- その時に、パッと英語で数学用語がでないと困る
- また、LatexはMarkdownで記述する時によく使う
- そこで、Latexと英語とRでの数学用語の基本的なメモを残す
NOTE:
- 便宜上形式的にLaTeXをLatexと表記する
LaTex
論理学系用語
これで基本的な用語は充足しているだろう。
| 日本語 | 英語 | 説明 |
|---|---|---|
| 公準 | Postulate | 証明されないが自明とみなされる命題(特に幾何学で) |
| 公理 | Axiom | 自明かつ不証明の前提 |
| 定義 | Definition | ある用語、記号、概念の正確な意味を明示するための文 |
| 原理 | Principle | ある分野で理論構築の基盤となるような、基本的な法則や概念 |
| 命題 | Proposition | 真または偽であると判断できるもの |
| 定理 | Theorem | 数学における重要な命題 |
| 公式 | Formula | 数学的な関係を表現する式 |
| 系 | Corollary | 他の定理や命題から直接導出される命題 |
| 法則 | Law | 実験や観測に基づいて確立された一般的な原理や規則 |
| 前提 | Premise | 論理的な推論や数学的証明における出発点となる命題や仮定 |
| 条件 | Condition | ある命題、定理、または論理的結論が成り立つために必要な仮定や要件 |
| 仮説 | Hypothesis | 未だ証明されていない命題や仮定 |
| 証明 | Proof | ある命題が真であることを論理的に示す過程 |
| 補題 | Lemma | 主要な定理や命題の証明を容易にするために用いられる、補助的な命題 |
| 推論 | Inference | 既知の事実や命題から新たな結論を導く論理的なプロセス |
変数(variable)
$$ x = 10 $$
変数の修飾
- 全ての変数(all variable)
- $n$の下付き文字で定義時に表す
$$ X = X_1, X_2, \cdots ,X_n $$
- 各変数(every variable)
- n項演算子と$i$の下付き文字で表す
$$ S = \sum_{i=0}^{n}X_i $$
- 任意の変数(any variable)
- n項演算子なしの場合は、$i$の下付き文字で表す
$$ E(X_i) = \mu $$
アクセント
- 循環小数
$$ \dot{a} = 0.9999 $$
- 推定値
$$ \hat{x} = 12 $$
- 平均
$$ \bar{x} = 12 $$
- 複素共役と補集合
- (エルミート共役と紛らわしいので、アスタリスクではなくバーで表す)
$$ \bar{z} $$
- 随伴行列(エルミート共役)
- 随伴行列はアスタリスク
$$ A^{*} $$
R
| |
ドットは単なる名前(dataオブジェクととかではない)
| |
型の意味
| 関数 | 意味 |
|---|---|
| typeof() | R言語視点のType |
| class() | クラスのtype |
| mode() | S言語視点(Becker, Chambers & Wilks視点)のType |
型の例
| |
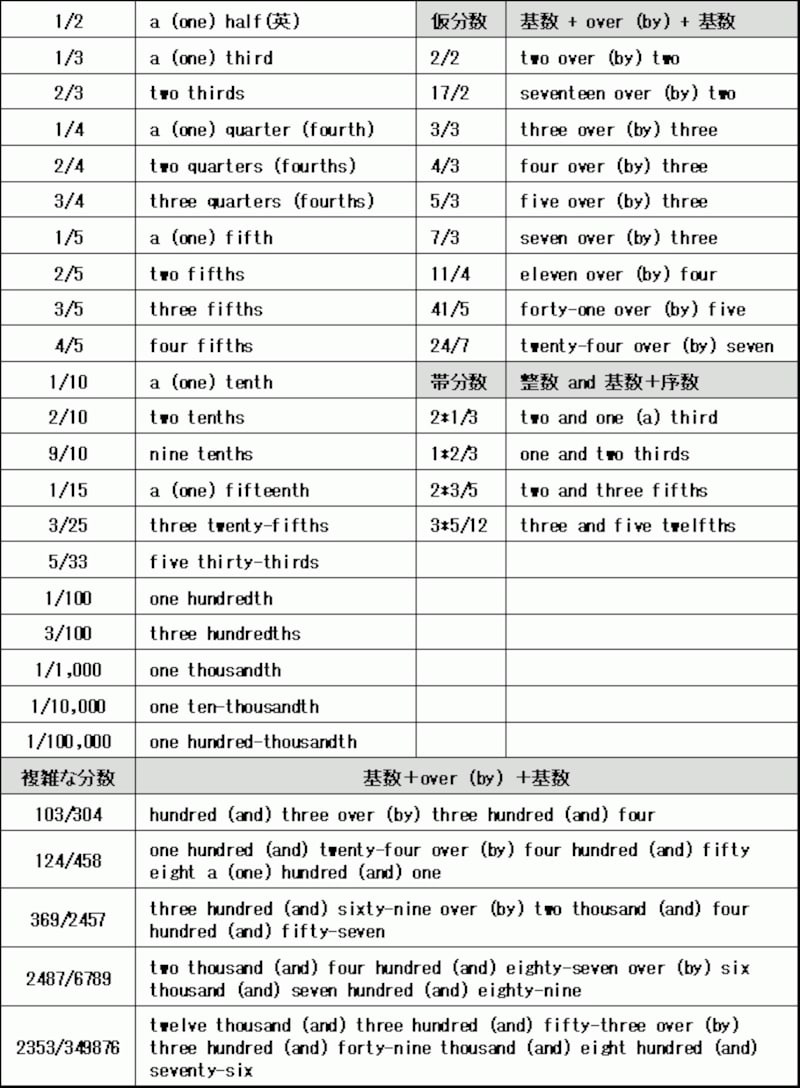
分数(Fraction)
| 出力 | $\TeX$ |
|---|---|
| $\frac{a}{b}$ | \frac{a}{b} |
英語での分数の読み方のルールは次になる。
- 分母は「denominator, denom.」
- 分子は「numerator, numer.」
- 分数を「分子 -> 分母」の順で読む
- 分子は基数(cardinal numbers)を使う
- 分母は序数(ordinary numbers)を使う
- 序数は次の2つの意味がある
- Third: 3番目
- Third: 1/3
- 序数は次の2つの意味がある
- ただし以下に注意
- 1/1の時
- one whole
- one over one
- 分子が0の場合
- zero thirds(0/3)
- 分子が1
- 分子はaかoneで、分母は単数形
- 分母が2の時
- one half (1/2)
- a half (1/2)
- one second (1秒) <= 間違い
- half a second (0.5秒)<= 間違い
- 分母が3の時
- one third (1/3)
- 分母が4の時
- a quarter
- one fourth <= よりフォーマル
- 分母が2の時
- 分子はaかoneで、分母は単数形
- 分子が1より大きい
- 分母は複数形
- 分母が2の時
- two halves(2/2)
- two seconds (2秒) <= 2秒なので注意
- 分母が3の時
- two thirds(2/3)
- 分母が4の時
- two quarters(2/4)
- two fourths(2/4) <= これは一般的ではない
- 分母が5, 6の時
- two fifths(2/5)
- two sixths(2/6)
- three twelfths(3/12)
- 分母が巨大な時
- one hundredth (1/100) <= これでもOK
- one over one hundred (1/100) <= こっちが一般的
- 分母が2の時
- 分母は複数形
- 分子や分母が少数の時は
- one point four fifths
- one point five over three
- one point five divided by three
- 帯分数の場合はandで繋げる
- three and a half (3 + 1/2)
- three times one-half (3 x 1/2)
- 分母が分子より大きいとき
- 5 out of 10
- 1/1の時
- その他
- tenth of a millimeter(ミリメートルの十分の一)
記号(symbol)
| 出力 | $\TeX$ |
|---|---|
| $=$ | = |
| $+$ | + |
| $-$ | - |
| $\times$ | \times |
| $\div$ | \div |
| $\pm$ | \pm |
| $\mp$ | \mp |
| $\neq$ | \neq |
| $\sim$ | \sim |
| $\simeq$ | \simeq |
| $\fallingdotseq$ | \fallingdotseq |
| $\risingdotseq$ | \risingdotseq |
| $\equiv$ | \equiv |
| $>$ | > |
| $<$ | < |
| $\geq$ | \geq |
| $\geqq$ | \geqq |
| $\leq$ | \leq |
| $\leqq$ | \leqq |
| $\gg$ | \gg |
| $\ll$ | \ll |
| $\oplus$ | \oplus |
| $\ominus$ | \ominus |
| $\otimes$ | \otimes |
| $\oslash$ | \oslash |
| $\circ$ | \circ |
| $\cdot$ | \cdot |
| $\cdots$ | \cdots |
| $\bullet$ | \bullet |
| $\in$ | \in |
| $\ni$ | \ni |
| $\notin$ | \notin |
| $\subset$ | \subset |
| $\supset$ | \supset |
| $\subseteq$ | \subseteq |
| $\supseteq$ | \supseteq |
| $\cap$ | \cap |
| $\cup$ | \cup |
| $\emptyset$ | \emptyset |
| $\infty$ | \infty |
集合(set)
- 集合は大文字
- 元(要素)は小文字
$$ X = \{x_1, x_2, x_3\} $$
特徴づけ(characterize)
- 性質P(property)が対象Xを特徴づける
$$ X = \{x | P(X) \} $$
- もしくは条件
$$ X = \{x | x \in \mathbb{R} \} $$
条件付き確率($P(X|C)$)の場合は括弧、特徴付けは波括弧の中でパイプをつかう
集合の関係
| 出力 | $\TeX$ |
|---|---|
| $\in$ | \in |
| $\ni$ | \ni |
| $\notin$ | \notin |
| $\subset$ | \subset |
| $\supset$ | \supset |
| $\subseteq$ | \subseteq |
| $\supseteq$ | \supseteq |
| $\cap$ | \cap |
| $\cup$ | \cup |
| $\emptyset$ | \emptyset |
| $\infty$ | \infty |
数の集合(Set of numbers)
| 意味 | 出力 | $\TeX$ |
|---|---|---|
| 自然数 | $\mathbb{N}$ | \mathbb{N} |
| 整数 | $\mathbb{Z}$ | \mathbb{Z} |
| 有理数 | $\mathbb{Q}$ | \mathbb{Q} |
| 実数 | $\mathbb{R}$ | \mathbb{R} |
| 複素数 | $\mathbb{C}$ | \mathbb{C} |
例
$$ 3\in\mathbb{N} \\ 3.14\notin\mathbb{Z} \\ \mathbb{Q}\subset\mathbb{R} \\ $$
関数(function)
関数
$$ y = f(x) = 2x $$
関数の引数が複数の場合。
コロンの場合は、複数引数を使う。
$$ f(x, x_2) = x + x_2 $$
セミコロンの場合は、セミコロンの前は変数、セミコロンの後はパラメータとなる。
$$ f(x; a,b) = (x^a)e^{(-x/b)} $$
セミコロンの意味:
- $f(x; a, b)$ はパラメータ$a, b$によって特徴付けられる、$x$変数の関数$f$みたいなイメージ
- つまり、$a,b$は係数としての性格が強く、$a,b$を固定して$x$の関数と見なすことが多い
ベクトル関数
$$ \mathbf{y} = \mathbf{a}(x) $$
写像
$$ f: \mathbb{R} \mapsto \mathbb{R} $$
場合分け
$$ y = \begin{cases} 1 & (n=0) \\ x^{n-1} & (otherwise) \end{cases} $$
R
| |
集計関数(aggregate function)
総乗
$$ f(x) = \sum_{i=0}^n x_i $$
総乗
$$ f(x) = \prod_{i=0}^n x_i $$
集合を使った場合
$$ f(x) = \sum_{i\in N} x_i $$
R
- max / min / which.max / which.min 最大値/ 最小値/ 最大値のある場所 / 最小値のある場所
- unique 重複除去
- sum / mean / median / var 合計 / 平均値 / 中央値 / 不偏分散
三角関数(trigonometric function)
| 出力 | $\TeX$ |
|---|---|
| $\sin x$ | \sin x |
| $\cos x$ | \cos x |
| $\tan x$ | \tan x |
| $\csc x$ | \csc x |
| $\sec x$ | \sec x |
| $\cot x$ | \cot x |
| $\arcsin x$ | \arcsin x |
| $\arccos x$ | \arccos x |
| $\arctan x$ | \arctan x |
| $\sinh x$ | \sinh x |
| $\cosh x$ | \cosh x |
| $\tanh x$ | \tanh x |
R
| |
ギリシャ文字(greek letters)
| 出力 | $\TeX$ | 出力 | $\TeX$ | 読み方 |
|---|---|---|---|---|
| $A$ | A | $\alpha$ | \alpha | アルファ |
| $B$ | B | $\beta$ | \beta | ベータ |
| $\Gamma$ | \Gamma | $\gamma$ | \gamma | ガンマ |
| $\Delta$ | \Delta | $\delta$ | \delta | デルタ |
| $E$ | E | $\epsilon$ | \epsilon | イプシロン |
| $Z$ | Z | $\zeta$ | \zeta | ゼータ |
| $H$ | H | $\eta$ | \eta | イータ |
| $\Theta$ | \Theta | $\theta$ | \theta | シータ |
| $I$ | I | $\iota$ | \iota | イオタ |
| $K$ | K | $\kappa$ | \kappa | カッパ |
| $\Lambda$ | \Lambda | $\lambda$ | \lambda | ラムダ |
| $M$ | M | $\mu$ | \mu | ミュー |
| $N$ | N | $\nu$ | \nu | ニュー |
| $\Xi$ | \Xi | $\xi$ | \xi | クシー |
| $O$ | O | $o$ | o | オミクロン |
| $\Pi$ | \Pi | $\pi$ | \pi | パイ |
| $P$ | P | $\rho$ | \rho | ロー |
| $\Sigma$ | \Sigma | $\sigma$ | \sigma | シグマ |
| $T$ | T | $\tau$ | \tau | タウ |
| $\Upsilon$ | \upsilon | $\upsilon$ | \upsilon | ユプシロン |
| $\Phi$ | \Phi | $\phi$ | \phi | ファイ |
| $X$ | X | $\chi$ | \chi | カイ |
| $\Psi$ | \Psi | $\psi$ | \psi | プシー |
| $\Omega$ | \Omega | $\omega$ | \omega | オメガ |
変数
| 出力 | $\TeX$ | 読み方 |
|---|---|---|
| $\varepsilon$ | \varepsilon | イプシロン |
| $\vartheta$ | \vartheta | シータ |
| $\varrho$ | \varrho | ロー |
| $\varsigma$ | \varsigma | シグマ |
| $\varphi$ | \varphi | ファイ |
数列(sequence)
$$ x = \{1, 2, 3\} $$
指数(exponential)
| 出力 | $\TeX$ |
|---|---|
| $\exp x$ | \exp x |
指数関数のグラフ。
- 定義域(domain)
- (-∞,∞)
- 値域(range)
- (0,∞)
R
| |
ネイピア数はexp(1)で表現する
| |
級数(series)
$$ s = \sum_{i=0}^{n}x_i $$
R
| |
区間(interval)
開区間
$$ x = (1, 2, 3) $$
閉区間
$$ x = [1, 2, 3] $$
ベクトル(vector)
$$ \vec{a} = \mathbf{a} = (1, 2)^T $$
| 出力 | $\TeX$ |
|---|---|
| $\vec{x}$ | \vec{x} |
| $\overrightarrow{x} $ | \overrightarrow{x} |
| $\hat{x}$ | \hat{x} |
R
| |
累乗/冪乗(power)

表記
| 出力 | $\TeX$ |
|---|---|
| $e^x$ | e^x |
累乗と冪乗の違い
| 乗 | 意味 |
|---|---|
| 累乗 | 指数部が自然数 |
| 冪乗 | 指数部が実数 |
対数(Logarithm)
| 出力 | $\TeX$ |
|---|---|
| $\log x$ | \log x |
| $\log_a x$ | \log_a x |
| $\ln x$ | \ln x |
対数関数のグラフ。
- 定義(domain)
- (0,∞)
- 値域(range)
- (-∞,∞)
常用対数と自然対数
| - | 正式表記 | 省略表記 | 別表記 |
|---|---|---|---|
| 自然対数(底=e) | $log_{e} x$ | $log x$ | $ln x$ |
| 常用対数(底=10) | $log_{10} x$ | $log x$ | - |
| ニ進対数(底=2) | $log_{2} x$ | - | $lg x$ |
| 指数関数 | $e^x$ | - | $exp(x0$ |
- 対数は、底(base)$a$と真数(antilogarithm)$x$を使って $log_a x$ と書くのが正式な表記。
R
ちなみに、Rにはネイピア数の定数はないので、exp(1)を使う必要がある
| |
累乗根(root)
| 出力 | $\TeX$ |
|---|---|
| $\sqrt{x}$ | \sqrt{x} |
| $\sqrt[n]{x}$ | \sqrt[n]{x} |
- 平方根(Square Root)
- The square root of x
$$ \sqrt{x} $$
- 立方根(Cube Root)
- The cube root of x
$$ \sqrt[3]{x} $$
- N-th根
- The n-th root of n
$$ \sqrt[n]{x} $$
行列(matrix)
集合は小文字、行列は太字。
$$ \mathbf{A} = \begin{pmatrix} a & b \\ c & d \end{pmatrix} $$
R
| |
データフレーム (行列にヘッダをつけたもの)
| |
極限(limit)
| 出力 | $\TeX$ |
|---|---|
| $lim_{n \to \infty}$ | lim_{n \to \infty} |
微分(derivative)
微分・勾配記号(derivative symbol)
| 出力 | $\TeX$ |
|---|---|
| $\nabla$ | \nabla |
| $\partial$ | \partial |
1次微分
$$ \dot x = x^{\prime} = dx/dt=\frac{d x(t)}{d t}=\frac{d}{d t}\left(x(t)\right), $$
2次微分
$$ \ddot x = x^{\prime \prime} = d^{2}x/dt^{2}=\frac{d^{2} x(t)}{d t^{2}}=\frac{d^{2}}{d t^{2}}\left(x(t)\right), $$
偏微分
$$ \frac{\partial f(x,y)}{\partial x} =\partial_{x}f(x,y)=f_{x}(x,y), $$
積分(Integral)
$$ \int f(x)dx, \ g(x)=\int^{x} f(x’)dx’, \ \int_{\alpha}^{\beta} f(x)dx. $$
面積分(surface integral)
$$ \int\int_{S} f(x,y) , \mathrm{d}x , \mathrm{d}y $$
線積分(line integral)
$$ \quad \oint_{C} f(z){\rm d}z $$
組合せ(combination)
- 組み合わせ(combination)
- 順列(permutation)
- 斉次積(Homogeneous product)
| 出力 | $\TeX$ |
|---|---|
| ${}_nC_r$ | {}_nC_r |
| ${}_nH_r$ | {}_nH_r |
| ${}_nP_r$ | {}_nP_r |
階乗(factorial)
$$ 5! = 5 \times 4 \times 3 \times 2 \times 1 $$
まとめ
- 数字は民主的であり、証明は理路整然とした論理を求める
- 外国人にも伝わりやすいし、日常会話でも序数で条件を挙げると納得されやすい
- 故に正しく使って効率良くコミュニケーションを取るのが大事