
目次
背景
機械学習でも頻出する話題である混同行列について改めてまとめる。
前提
分類の全体像
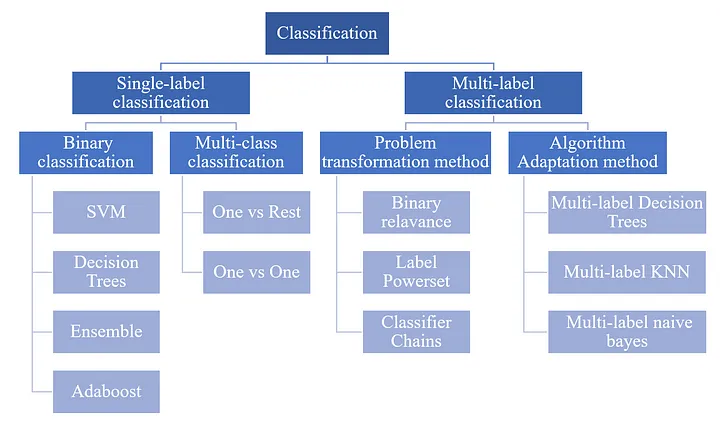
まず、分類には付けるlabelが単数か複数(単数もしくは複数)かによって、大きく2つの型がある。 その上で、今回は単数のSingle-label classificationを扱う。
- Single-label classification
- 二値分類(Binary Classification)
- 0か1などのように2つに分類するパターン
- 多クラス分類(Multi Class Classification=MCC)
- 1つのインスタンスに複数のクラスから1つのクラスが付くパターン
- 物体検知などで利用される
- multi-label classification
- 1つのオブジェクトに複数のラベルが付くパターン
- LLMなどでトークンのNER(Named Entity Recognition)分類などに使われる
マルチラベルとマルチクラスの違い
ややこしい為まとめると、次のように、マルチラベルとマルチクラスの違いがある。 一般的に、Single-labelのみ混合行列が適用可能になる。
| 特徴 | マルチラベル分類 | マルチクラス分類 |
|---|---|---|
| クラス割り当て | 各インスタンスに複数のラベルを割り当てる | 各インスタンスを一つのクラスに割り当てる |
| ラベルの数 | インスタンスごとに異なる数のラベル | 各インスタンスは一つのラベルのみを持つ |
| 典型的な使用例 | 映画のジャンル分類(例:アクション、ロマンス) | 動物の種類分類(例:犬、猫、鳥) |
| 混同行列の使用 | 伝統的な混同行列は適用しにくいが、適応された方法が使用される | 直接使用可能 |
| 評価指標 | ハミング損失、ラベルごとの精度・再現率・F1スコア | 全体の精度、クラスごとの精度・再現率・F1スコア |
ラベルとクラスの違い
微妙なニュアンスの違いがある。
- ラベル(Label):
- 個々のデータポイントに割り当てられる具体的なカテゴリ
- 例: メールが「スパム」や「非スパム」とラベル付けされる
- クラス(Class):
- 分類タスクにおける全ての可能なカテゴリのセットを指す
- 例: スパムメール分類タスクにおいて、可能なクラスは「スパム」と「非スパム」の2つ
つまり、ラベルはラベリングというように、個々の事例に焦点を当てており、 クラスはが識別することができる全てのカテゴリの集合を意味する。
ちなみに、オブジェクトとインスタンスも混合しがちだが、分類の文脈ではインスタンスが適切である。
混同行列とは
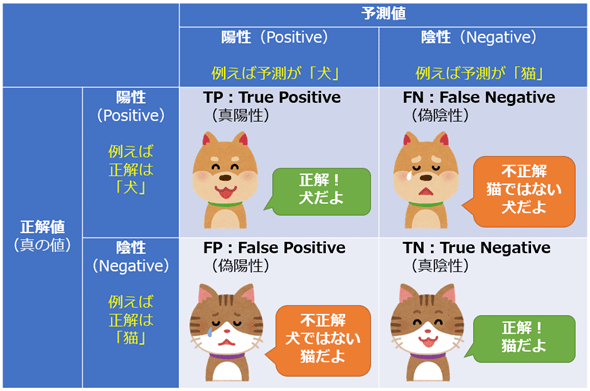
混同行列(Confusion Matrix)とは、機械学習の2値分類問題の分類結果をまとめた行列。 予測とその予想の正解かどうかの組み分けを表にまとめたもの。
二値分類
犬と猫の例
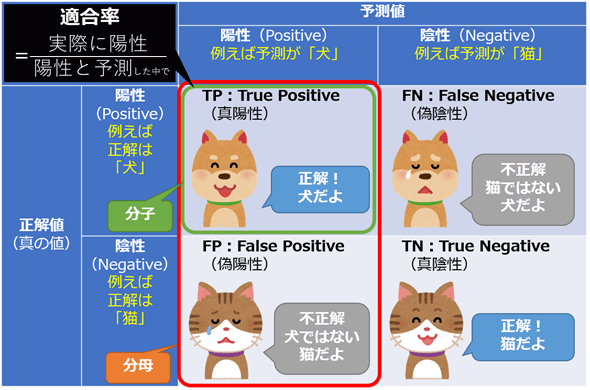
一目で分かりやすいのが次の画像。 次のマトリックスになっている。
- 行を正解ラベル
- 列を予測結果
評価指標
陽性 / 正例 (Positive)、 陰性 / 負例(Negative)
機械学習では正例 / 負例の翻訳をよく使う。 これは予測とGrand-Truthの予測ラベルにおけるPositive / Negativeの事を意味する。
- 陽性 / 正例(Positive): 予測対象の特定の状態または属性(例えば病気である、スパムであるなど)が存在する場合
- 陰性 / 負例(Negative): 予測対象の特定の状態または属性が存在しない場合
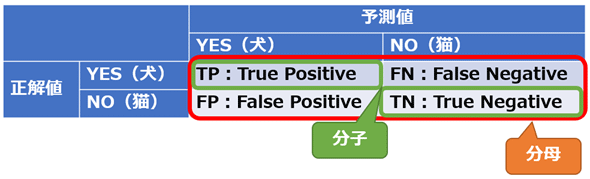
真陽性(TP) / 偽陽性(FP) / 偽陰性(FN) / 真陰性(TN)
予測結果と実際の正解ラベルを基にマトリックスを作ったのが、TP / FP / FN / TNである。
- 真陽性(TP, True Positive): モデルが陽性と予測し、実際に陽性であるケース
- 偽陽性(FP, False Positive): モデルが陽性と予測したが、実際には陰性であるケース
- 偽陰性(FN, False Negative): モデルが陰性と予測したが、実際には陽性であるケース
- 真陰性(TN, True Negative): モデルが陰性と予測し、実際に陰性であるケース

また、その割合はRateを付けて、TPR(陽性率)などと表現する。
正解率(Accuracy)
正解率は、全てのケースの中で正しく予測されたケース(TPとTN)の割合。
$$ Accuracy = \frac{(TP+TN)}{(TP+FP+FN+TN)} $$
誤答率(Error rate)
誤答率は、全てのケースの中で誤って予測されたケース(FPとFN)の割合。
$$ \text{Error Rate} = 1 - Accuracy $$
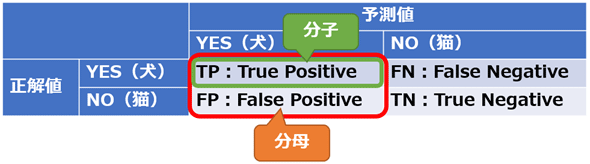
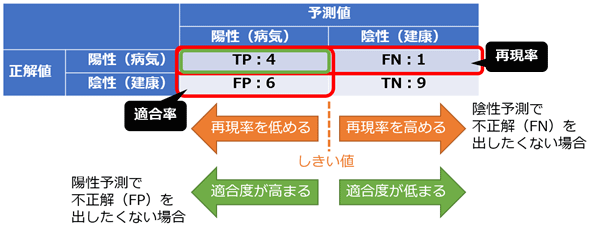
適合率 / 精度(Precision)
適合率は、陽性と予測されたケースの中で、実際に陽性である割合。
$$ Precision = \frac{TP}{(TP+FP)} $$
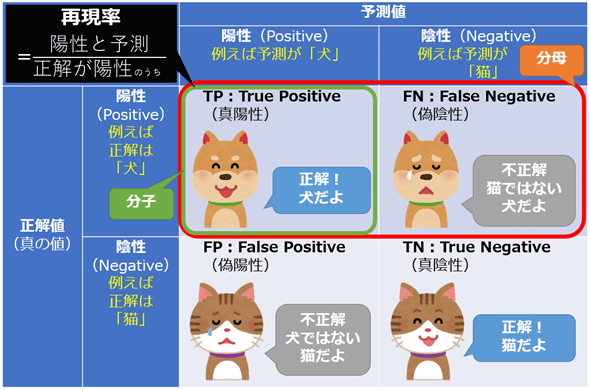
再現率(Recall)/ 感度(Sensitivity)
再現率は、実際に陽性であるケースの中で、正しく陽性と予測された割合。
$$ Recall = \frac{TP}{(TP+FN)} $$

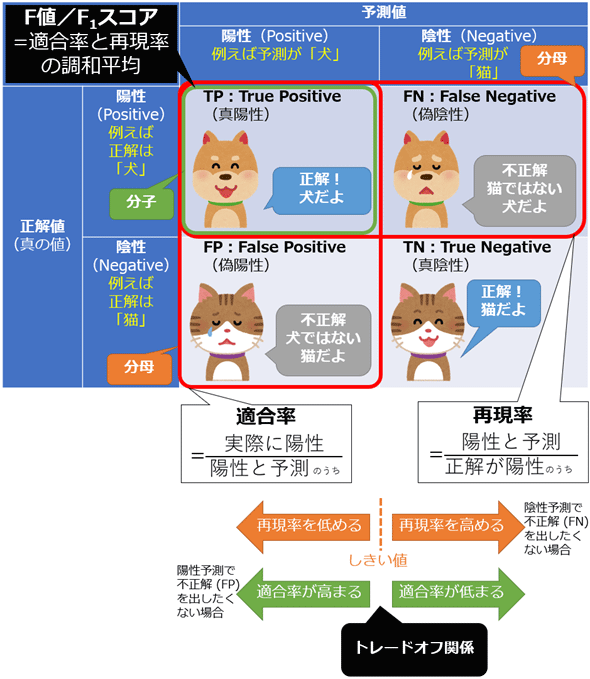
適合率と再現率のトレードオフ
- 適合率(Precision)と再現率(Recall)にはトレードオフの関係がある
- 簡単に言えば、スナイパーライフルとマシンガンの戦略の違いのようなもの
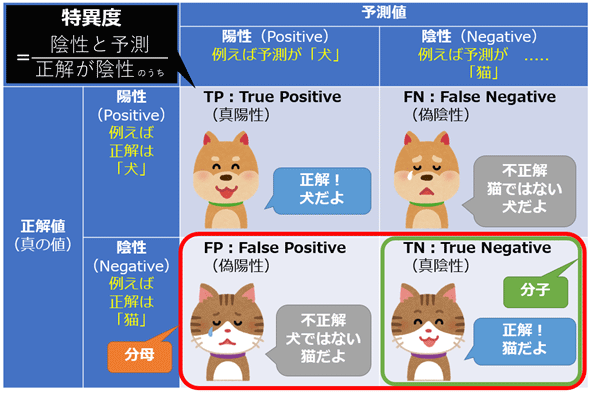
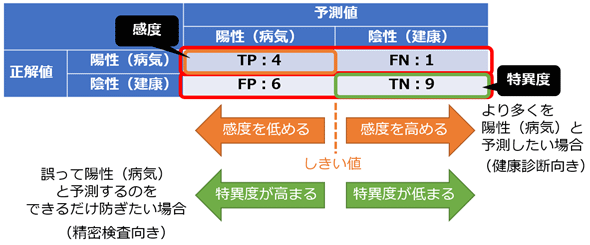
特異度(Specificity)
- 特異度は、実際に陰性であるケースの中で、正しく陰性と予測された割合。
- つまり、適合度のNegative版ということ
$$ Specificity = \frac{TN}{(TN+FP)} $$

特異度と感度のトレードオフ
- 特異度と感度(適合率)もまたトレードオフである
F値
F値 (F-measure)/ F1スコア(F1-score)
適合率と再現率のトレードオフ関係に着目し、調和平均を算出した値がF値(F-measure)。
$$ F_{1} = \frac{2 \times \text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} $$
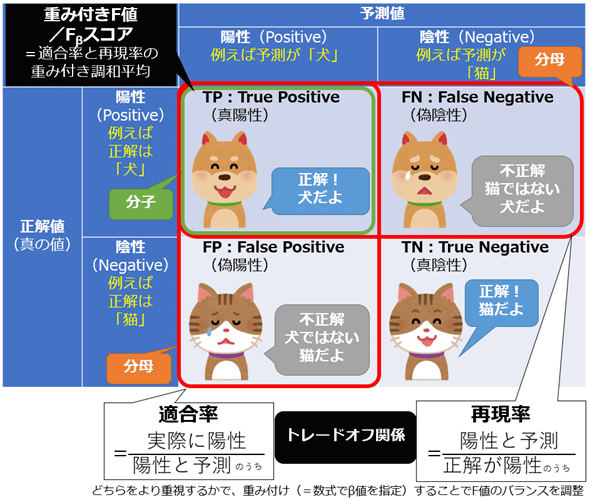
重み付きF値(Weighted F-measure)/ Fβスコア(Fβ-score)
- F値 / F1スコアは調和平均で、適合率と再現率をどちらも同じように扱った
- それのバランス調整をするのが、重み付きF値
- β>1なら再現率を重視し、β<1なら適合率を重視する
$$ F_{\beta} = \frac{\text{Precision} \times \text{Recall} \times (\beta + 1)}{\text{Precision} + \text{Recall} \times \beta^{2}} $$
マイクロF1とマクロF1
| 指標 | 計算方法 | 重視するもの |
|---|---|---|
| Macro-F1 | 各クラスのF1を単純平均 | 各クラスを平等に評価 |
| Micro-F1 | TP・FP・FNを全部合計 | 全サンプルの正解性能 |
| Weighted-F1 | データ数でF1を加重平均 | 多数クラスの性能 |
LogLoss(Binary Logarithmic Loss)
分類の正確さ(Accuracy)よりも、確率の高さ(Probability)を評価スコアとして取得したい場合に利用する。
- つまり、0, 1のカテゴリカル変数ではなく、[0, 1]の範囲と閾値を基にした確率的な評価スコアと言う事
- LogLossは[0, -∞]までの値域
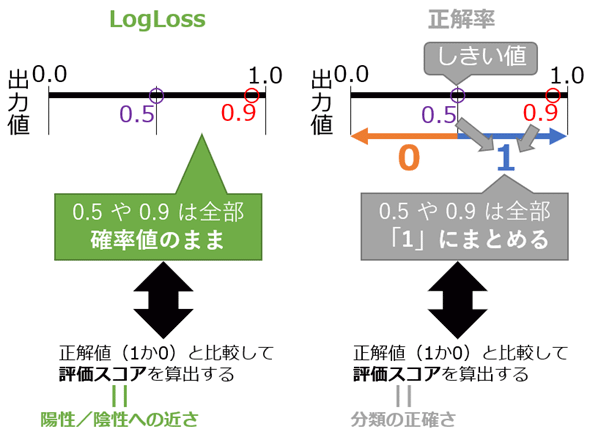
- また、交差エントロピー誤差(Cross entropy error)と考え方は一緒
- 平均二乗誤差(MSE:Mean Squared Error)との比較が次の画像
- 図の通り、両端の扱いが違う
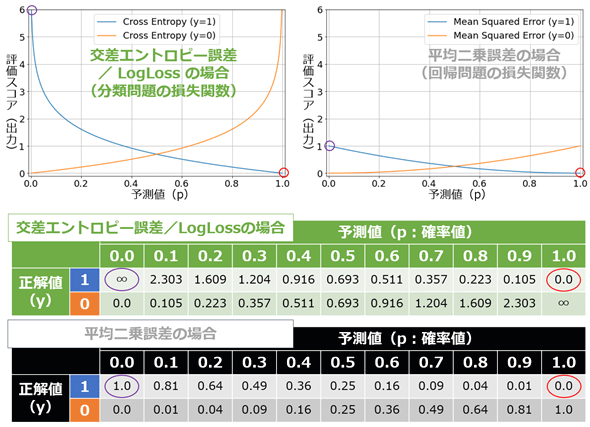
- 上記図の指数関数的な変化を
-log(p)としてマイナス自然対数を使う - すると、pを確率、-log(p)を正解との誤差に利用している
- 0は不正解で、1は正解である
- 下のloglossはクロスエントロピー誤差である
- nはクラス数、y_iは正解ラベル、p_iは予測結果を示している
$$ LogLoss = - \frac{1}{n} \sum_{i=1}^n (y_i log p_i + (1- y_i) log(1-p_i))) $$
ポイント系
カットオフポイント(cutoff point)
- PR曲線やROC曲線を出すのに閾値を複数用いて評価スコアを算出し、総合的にモデルの性能の評価をする必要がある
- その閾値の事をカットオフポイントと言う
- 例えば、閾値の数が200個なら、ある閾値のレンジを200分割し、それぞれを閾値(カットオフポイント)として利用する
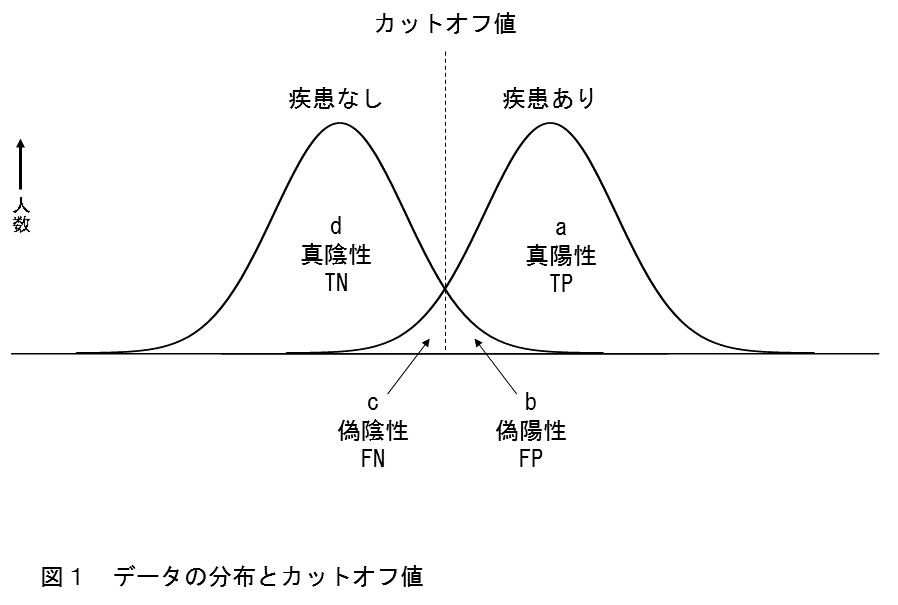
- データの分布とカットオフ値の関係を上に示す
- モデルが完全にPositiveとNegativeを予測できない限り、Grand-truthのPositiveとNegativeの分布は重なる
- カットオフより+はPositiveと予測し、カットオフより-はNegativeと予測している事を意味する
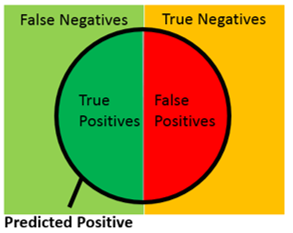
- 分布をベン図で示すと上になる
ブレイクイブンポイント
- ブレイクイブンポイント(BEP)は、適合率と再現率が等しくなる点を指す
- この点は、モデルが偽陽性と偽陰性を同じ程度に重視している状態を示し、PR曲線上で見つけることができる
- BEPはモデルの全体的なバランスを理解するのに役立つ
AUC系
AUCの目的
- 機械学習モデルの性能を比較するためなど、モデルの精度(=性能)をより汎用的に計測したい場合に利用する
- 正解率よりも優れている利点としては、AUCはしきい値の影響を受けないことが挙げられる
- 正解率は、デフォルトで0.5をしきい値として、予測値は0.5以上なら1、0.5未満なら0という形で評価値が決まる
- つまり、このしきい値は変えることもできるが、その場合、評価値も変わってしまうという問題があると言う事
AUCは二種類ある
- 通常の、ROC曲線を使ったAUC
- PR曲線を使ったPR-AUC(Area Under the Precision-Recall Curve、AUC-PR)
通常はROC曲線を使ったAUCをAUCと表記する。
AUC(Area Under the ROC Curve)
- AUC(Area Under the Curve)はROC曲線(Receiver Operating Characteristic curve)の下の面積
- 値域は[0, 1]で、高いほどいい精度を示す
- AUCは特に不均衡なデータセットでのモデルの性能を評価するのに有効
ROC曲線(Receiver Operating Characteristic curve:受信者操作特性曲線)とAUC
- ROC曲線は、異なるしきい値における真陽性率(TPR)と偽陽性率(FPR)の関係をプロットしたグラフ
- 曲線が左上に近づくほどモデルの性能が高いと評価される
- ROC曲線は、特にバイナリ分類問題においてモデルの診断能力を評価するのに役立つ
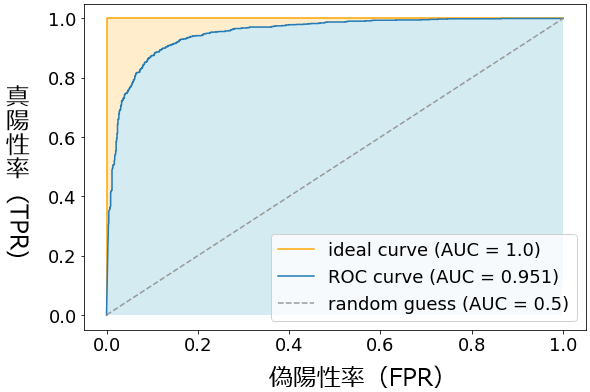
- AUCグラフは、X軸はFPR、Y軸はTPRで成り立つ
- 上図の水色の領域の面積がAUCの値
- ランダムに推測(random guess)するモデルだと、基本的にAUCは0.5となる
意味は次になる。
- 0.9~1.0: 非常によい(excellent)
- 0.8~0.9: よい(good)
- 0.7~0.8: まあまあ(fair)
- 0.6~0.7: よくない(poor)
- 0.5~0.6: 失敗(fail)
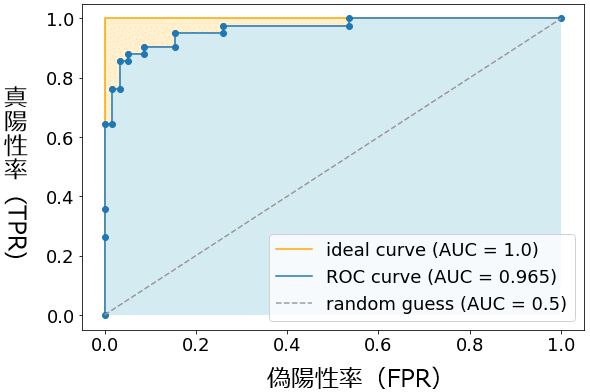
ROC曲線の描き方。
- 閾値を変えてTPRとFPRを計測する
- 元々、感度や特異度では分類判定のしきい値を指定していた
- しかし、AUCの真陽性率&偽陽性率では0.0~1.0の範囲でしきい値を細かく指定していく
- この閾値を(threshold value=カットオフポイント:
cutoff points(分割点))と言う - 例えば、cutoff pointsを200とすると、[0, 1]を200分割して計測してグラフを描写することになる
- 下の画像はその一例となる
PR曲線とPR-AUC(Area Under the Precision-Recall Curve、AUC-PR)
- PR曲線(Precision-Recall curve)は、適合率(Precision)と再現率(Recall)の関係をプロットしたグラフ
- 特に陽性クラスのサンプルが少ない不均衡なデータセットにおいて、モデルの性能を評価するのにPR-AUCは有効
- PR曲線では、曲線が右上に近づくほどモデルの性能が良いとされる
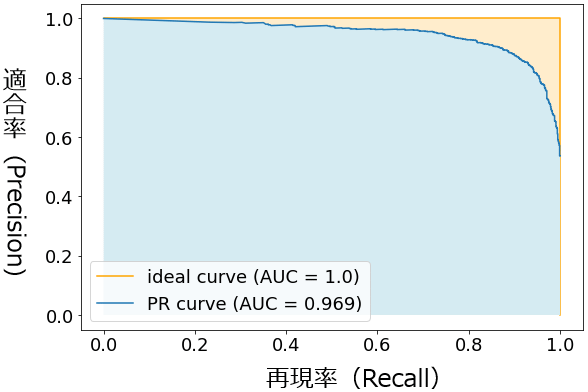
- PR-AUCグラフは、X軸は適合率(Precision)、Y軸は再現率(Recall)で成り立つ
- PR曲線はROC曲線と同じように閾値を変更してプロットする形になる
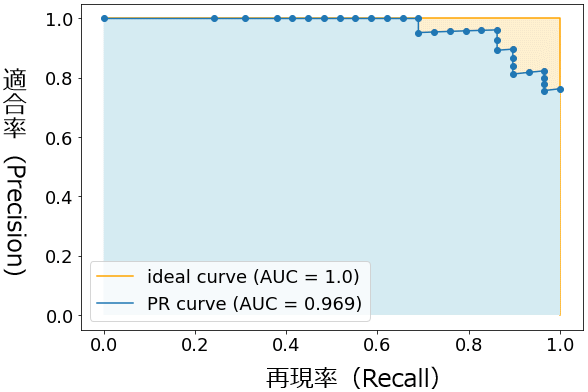
そもそも適合率と再現率はトレードオフ関係にあり、再現率(x軸)の数値が大きくなるにつれて、適合率(y軸)は小さくなる。
ROC曲線とPR-ROC曲線の違い
- ROC曲線では、ランダムに推測(random guess)すると、基本的にAUCは0.5
- 他方、PR-ROC曲線はランダムに予測しても、陽性と陰性のデータ数の割合によって数値が変わる
- よってPR-AUCは、ROC曲線のAUCと比べて「モデルの汎用的な精度の測定や比較という用途にはあまり向いていない」ともいえる
値系
閾値
- モデルの分類スコアをベースに属するか属さないかを決める為のスコア
評価スコア
- これはTPRやAUCなど、性能の評価として取った代表値の総称の事
分類スコア
- 分類スコアは、分類モデルが特定のクラスに属する確率を示す数値
- このスコアは、モデルがどの程度自信を持って、予測を行っているかを示している
- しきい値を調整することで分類の精度を変えることができる
Average Precision系
適合率 / AP(Average Precision)
- 平均適合率(AP)は、異なるしきい値で計算された適合率の平均を意味する
- APはPR曲線の下の面積としても解釈され、モデルの平均的な適合率の性能を示す
- 不均衡データで有効
平均適合率 / mAP(mean Average Precision)
- mAP(mean Average Precision)は、複数のクラスまたは複数の検出タスクに対するモデルの平均適合率の平均
- これは、特にオブジェクト検出やマルチクラス分類問題でよく使用される指標で、モデルが全体的にどれだけうまく機能しているのかを判断する指標
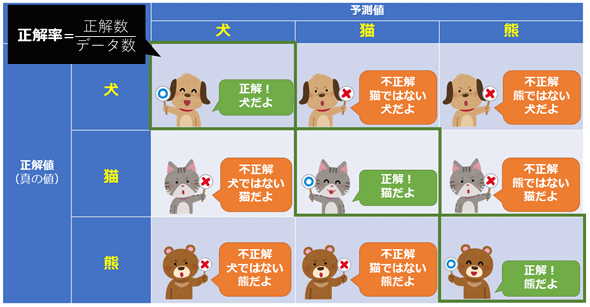
多クラスの混同行列
分かりやすい例
- 下の画像が一番わかりやすい
- 多クラス分類の場合でも、二値分類の場合と同様にTP / FP / FN / TNを計算できる
- ただし、クラス毎に計算する
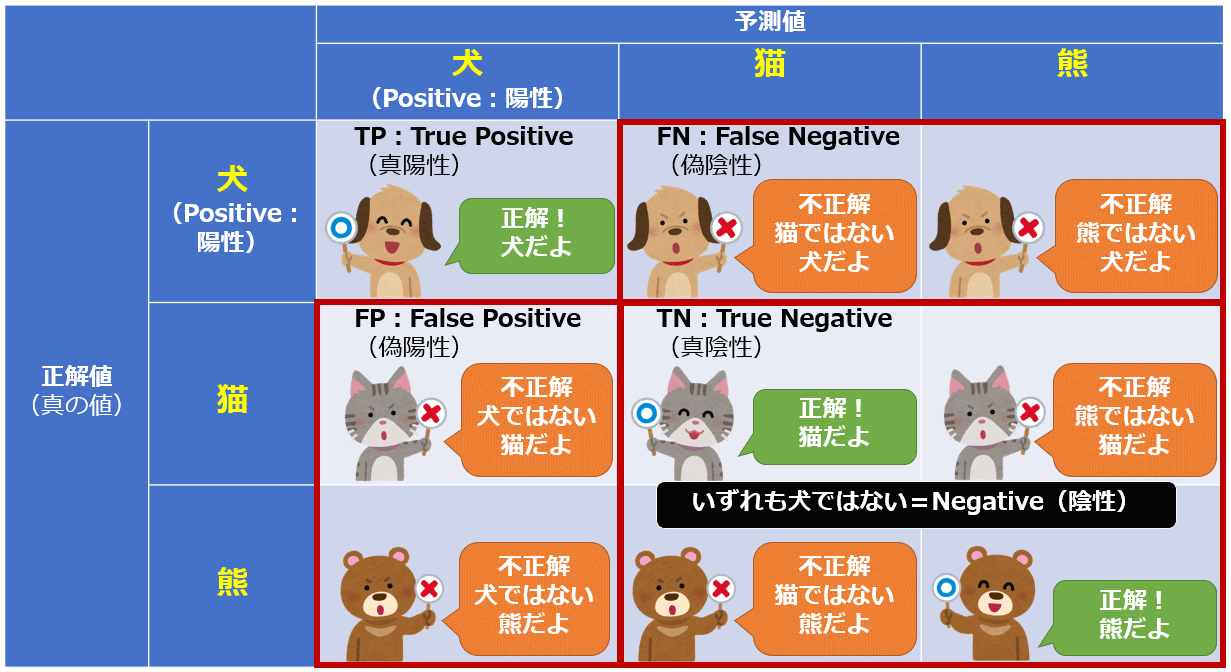
- 上の例では、犬を陽性とするバージョンと同様に、猫を陽性とするバージョンと、熊を陽性とするバージョンの計3パターンを考える必要がある
- つまり、クラスの数だけ「二値分類の混同行列」を作るという事
- また、全体的な評価方法として、マクロ平均とマイクロ平均がある
- 例えば、F1スコアもMicro-F1スコアやMacro F1スコアなどのように分かれる
マクロ平均(Macro Average)
- 各クラスごとに指標を計算し、その後でこれらの平均を取る
- つまり、これは各クラスを同等に扱うことを意味する
- 故に、不均衡データにおいては、マクロ平均を使った方が良い
マイクロ平均(Micro Average)
- 全クラスにわたって集計された真陽性(TP)、偽陽性(FP)、偽陰性(FN)の値を使用して指標を計算する
- つまり、個々のクラスよりも全体のパフォーマンスに焦点を当てるアプローチ
マクロ平均とマイクロ平均の使い分け
- マイクロはクラス毎のTF / FP / FN / TPなどを計算し合算して評価スコアを出す
- 故に、少数のデータしかないクラスのでーたががあったとしてもそれは反映されにくい
- 逆に、マクロ平均はTP / TN / FP / FNなどをクラスごとに計算して代表値を出しその平均を取る
- 故に、マクロ平均は少数のデータでも代表値を出し別のクラスと同様に扱うため、不均衡データに適する
バイアス
特徴選択のバイアス
みにくいアヒルの子の定理(Ugly Duckling theorem)
- 事前の知識や仮定がなければ、あらゆる物事は同程度に似ている(または異なっている)というもの
- つまり、特定の特徴や属性を重視するかどうかは、その特徴がどのように重要視されるか(または無視されるか)によって決まる
- つまり、特徴選択(Feature Selection)というバイアス(人間の主観性)によって、前提が決まると言う事を示している
学習のバイアス
Inductive Bias
- 機械学習における学習アルゴリズムが、学習データから一般化する際に持つ、事前の仮定や傾向を指す
- 別言い方だと、アルゴリズムが未知のデータに適用された際にどのような予測を行うかに影響を与える、アルゴリズム固有のバイアス
- inductive biasは過度な単純化や過学習(Overfitting)を起こす
データのバイアス
不均衡データの問題
データセット内の異なるクラス(カテゴリー)が非常に不均等な割合で存在する状態の事。
例
- クレジットカードの不正使用検出のようなケースでは、
- 不正なトランザクション(異常)は正常なトランザクションに比べて非常に少なく、データセットは不均衡になる
- この場合、単純な精度(Accuracy)だけでモデルを評価すると誤解を招く可能性がある
- なぜなら、モデルがすべてのトランザクションを「正常」と予測しても高い精度を示すから
オーバーサンプリング、アンダーサンプリング
- オーバーサンプリングは、少数派クラスのデータポイントを増やすことでクラス間の不均衡を解消する
- アンダーサンプリングは、多数派クラスのデータポイントを減らすことでバランスを取る
合成データ生成(Synthetic Data Generation)
主に次の3つの手法を利用する。
- データ拡張(Data Augmentation)
- GANsで生成
- 統計的シミュレーション
試験者によるバイアス
ブラインド検査(Blind Testing)
- 主観的なバイアスを排除するための検査方法
- 実験の被験者や評価者がどのサンプルや治療を受けているかを知らない状態で行う検査
ランダム比較試験(RCT: Randomized Controlled Trial)
RCTは医学や心理学、教育学など多くの分野で用いられる、科学的な研究の手法。
- コアは被験者をランダムに対照群(コントロールグループ)と実験群(治療群または介入群)に割り当てること
- これにより、他の変数が結果に与える影響を最小限に抑え、介入の効果をより正確に評価することができる
ランダムサンプリング
- 母集団からランダムサンプリングしないデータはbiasedなデータになる
- 恣意的にデータを選択しないようにするため、分割や抽出はランダムに行う
その他
野球と混合行列
野球と混合行列を考えるとわかりやすい。
| 実際 \ 判定 | ストライク | ボール |
|---|---|---|
| ストライクゾーン | True Positive (TP) | False Negative (FN) |
| ボールゾーン | False Positive (FP) | True Negative (TN) |
- Recallを上げる
- 本当はストライクの球を見逃さない
- 多少ボール球をストライクと言ってしまっても、ストライクを多く拾う方向
- Precisionを上げる
- ストライクと言った球の正確さを上げる
- 怪しい球はボールにして、本当にストライクの球だけをストライクと言う方向
TP FPなどの覚え方
TP/FPなどは、次のように考えると分かりやすい。
予測が正しいかどうかで次の2つ。
- True
- False
予測結果は次の2つ。
- Positive
- Negative
それを組み合わせると次になる。
- TP // 正しくPositiveと予測(正解はPositive)
- FP // 間違ってPositiveと予測(正解はNegative)
- FN // 間違ってNegativeと予測(正解はPositive)
- TN // 正しくNegativeと予測(正解はNegative)
AccuracyとPrevisionのトレードオフ
下の図が一番わかりやすい。
- Accuracyは真値からの分布全体のズレ
- Precisionは分布のばらつき度合
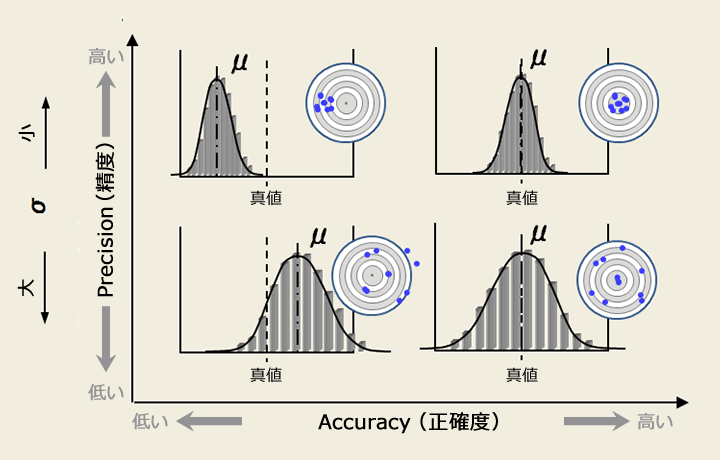
算術平均と調和平均
- 調和平均(Harmonic Mean)
率の平均を算出するのに適している。
- 算術平均(Arithmetic mean)
量の平均を算出するのに適している
例:
ある車が100キロメートルの距離を行く際には時速50キロメートル、 帰る際には時速100キロメートルで移動した時、往復の平均速度は何キロメートル/hか?
- 算術平均 = $\frac{(50 + 100)}{2} = 75$
- 調和平均 = $\frac{2}{\frac{1}{50}+\frac{1}{100}}=66.67$
Scikit-learn
利用するMatrixの関数
混合行列を作る時に、scikit-learnではそれぞれ次の関数を使う。
- 二値分類の場合:
- sklearn.metrics.confusion_matrix()
- 多クラス分類の混同行列の場合:
- sklearn.metrics.multilabel_confusion_matrix()関数
Scikit-learnでの例
二値分類の場合のScikit-learnでの例。
| |
参考文献
第10回 機械学習の評価関数(二値分類用)の基礎を押さえよう:TensorFlow 2+Keras(tf.keras)入門 - @IT
第11回 機械学習の評価関数(二値分類/多クラス分類用)を理解しよう:TensorFlow 2+Keras(tf.keras)入門 - @IT
(12) 【続報】線虫がん検査は有効か。全国規模の調査開始。【HIROTSU社、反論文を公開】線虫くん/広津社長/がん検診/N-NOSE(解説:須田桃子) - YouTube
多クラス分類の混同行列(Confusion matrix for multi-class classification)とは?:AI・機械学習の用語辞典 - @IT
Multi-label Classification. For most of the classification… | by Wimukthi Madhusanka | Medium
[評価指標]AUC(Area Under the ROC Curve:ROC曲線の下の面積)とは?:AI・機械学習の用語辞典 - @IT
sklearn.metrics.multilabel_confusion_matrix — scikit-learn 1.3.2 documentation
第10回 機械学習の評価関数(二値分類用)の基礎を押さえよう:TensorFlow 2+Keras(tf.keras)入門 - @IT
第10回 機械学習の評価関数(二値分類用)の基礎を押さえよう:TensorFlow 2+Keras(tf.keras)入門 - @IT
第10回 機械学習の評価関数(二値分類用)の基礎を押さえよう:TensorFlow 2+Keras(tf.keras)入門 - @IT
医療・介護・リハビリでの検査・測定データの読み方~尤度比とは | セラピストプラス | 医療介護・リハビリ・療法士のお役立ち情報