
目次
概要
- FastAPIとPydanticでDDD likeなAIのシステム設計をした時の備忘録
- Djangoや他のMVC-likeなFWとは違い、コアにはPydanticのみを使用した
- サーバー構成は重い処理に対処するため非同期分散処理のアーキテクチャを採用した
- その時の実装のメモ(特にDDD周り)を備忘録として残した
- ADR(Architectural Decision Records)に近いWhyを残す
構成
処理内容
- AIの推論処理は次のような特徴がある
- 重い処理
- 場合に応じてマシンにGPUが必要
- CPU/GPUやRAM/VRAMバウンディングな処理
- 実行時間が長い
- 並列実行数の制限が必要
- そこで、推論処理は別サーバーに分離し非同期で行う事とした
- また、個別の推論処理に合わせてマイクロサービスに分離した
- 理由は推論処理に合わせて、インスタンスタイプを最適化するため
DBの選定
DBは次の理由からPostgresを採用した。
- 垂直スケールアップ型で対応可能な負荷だったため
- Pythonと相性のいいため
- 推論結果のリレーションが必要だったため
- NoSQL程のパフォーマンスは必要なかったため
テーブル設計
テーブルは次のようなエンティティを定義した。
- ユーザー(users)
- 画像データ(images)
- 分析結果(analysis)
- 推論結果(faces, quotes, etc..)
ID発番は将来的な分散処理を見越してUUIDv4を採用した。
NOTE: UUIDv3は別ホストで衝突する可能性がある。
アーキテクチャ
アーキテクチャには、プロデューサー / コンシューマーアーキテクチャを採用した。
マイクロサービスは20個ほど分離して処理毎に別インスタンスを用意した。
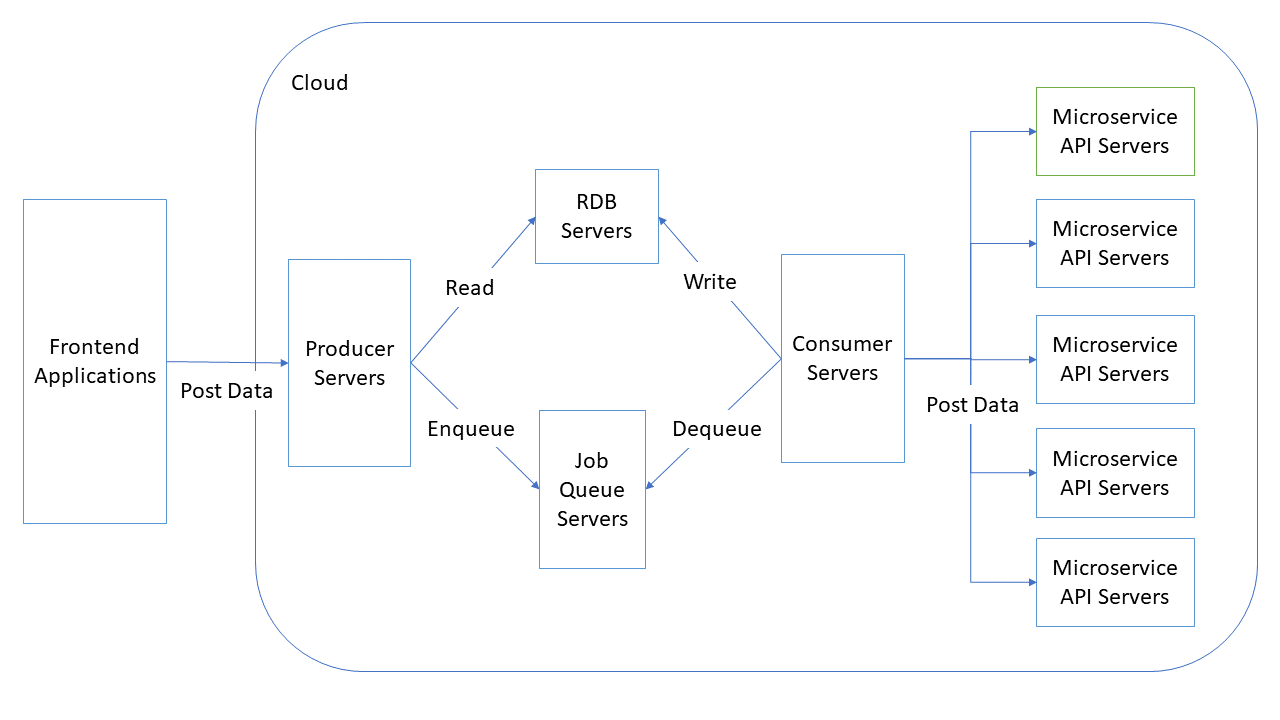
アクターは次になる。
- Frontend Application
- Producer Server(BFF)
- Consumer Server(Batch)
- Microservice Servers
大まかにフローは次のような流れである。
- Frontend ApplicationからProducer Serverにリクエストを投げる
- Producer ServerがJob Queue ServerにMessageをEnqueuする
- Consumer ServerがそのMessageをDequeueする
- Consumer ServerがMicroserviceの依存関係を解決して推論処理をMicroserviceにPostする
- Consumer ServerがDBに結果を記録する
- Producer ServerがDBの結果を取得する
プログラミング言語の選定
- GoかPythonが候補にあったがPytonに決定
- 理由はAIサービスと相性がいいため
- Go + gRPCもありだったがあくまで推論処理なのでPythonを選んだ
- 殆どのワークロードはAIの推論処理
- その推論処理はONNXを使うだけ
- プログラミング言語の差は問題ではない
- GPU, Memoryバウンディングの処理が多いため
- Goのようなcorutine(gorutine)で同時並行に処理する必要がなかった
- アーキテクチャで処理ごとに分散処理しているため
- 殆どのワークロードはAIの推論処理
- またgRPCのようにスキーマをmicroservice毎に定義せず、1つにまとめた
FWの選定
- Pydanticを採用した
- また、Web FWはPydanticと相性のよいFastAPIを採用
- OpenAPIを利用してドキュメント化できるのが良かった
- また、Web APIはNginxとそのローカルキャッシュを利用した
- テストはpytestで行った
Manager-Workerでの通信規格の統一化
- Microserviceの推論の結果としてMicroserviceRepresentationDTOに統一した
- 具体的には以下のようにPydanticでクラスを作り、それをベースにFastAPIのRequest型とした
- corutineで並列処理をする必要がないため、uvicornではなくgunicornなどのAPサーバーでも良かったのかもしれない
- そしてそれぞれの規格でタグ付き共用体でLiteralを利用する
| |
モジュール化
- 機能・責務ごとに別pythoin packageに分けてモジュールとして分割統治する
- DDDの流儀でまとめたビジネスロジックもそのモジュールの一つである
- 例えば、CVの共通処理は
xxxpj-cvみたいな形である - それらを
xxxpj/cv/ようにimplicit namespaceを置いて、別々モジュールも一つのnamespaceで一元管理する
分散システム
分散処理の通信パターン
上述のアーキテクチャ図からわかるように、今回は次の2つのパターンを採用した。
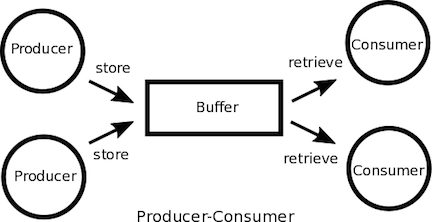
プロデューサー・コンシューマー
- プロデューサ・コンシューマパターンは、プロセスの役割をデータを登録(生産)するものと処理(消費)するものに区別しているパターン
- プロデューサーとコンシューマの間には仲介する有限のバッファで間接的に通信となり、両者間で非同期な通信をする
- ほかの言い方だと、メッセージキュー(Message Queue)パターン
- MessageはTaskとも呼ばれたりする
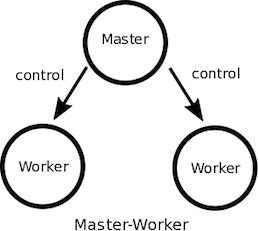
マスタ・ワーカー
- マスタ・ワーカーパターンはマスタ・スレーブ(Master Slave)モデルとも呼ばれるパターン
- 1つのマスタがプログラムの実行を管理し、そのプログラム全体や一部の処理の実行をワーカーに割り当てる
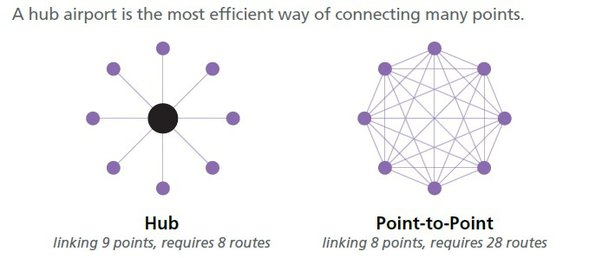
通信パターンの比較
クライアント・サーバーパターンとマスタ・ワーカーパターンの違いは次。
- クライアント : サーバー = N : 1
- マスター : ワーカー = 1 : N
また、N:Nの通信は次の2つのパターンがある。
- Hubパターン
- NodeはHubと通信するのでNodeの処理は楽になる
- ただし、Hubが単一障害点になる問題がある
- P2Pパターン
- BitcoinなどのCryptoのClientのパターン
- 非中央集権でありスケーラビリティに優れている
分散トランザクション
- トランザクションに関してはManagerのインスタンスでシングルトンのように一元的に状態を管理する
- つまり、Managerからのみ、RDBにのみ対してAtomicな処理が走るので、分散トランザクションにはならない
- そのため、TCCパターンとSagaパターンのような分散トランザクションのパターンの適用は不要だった
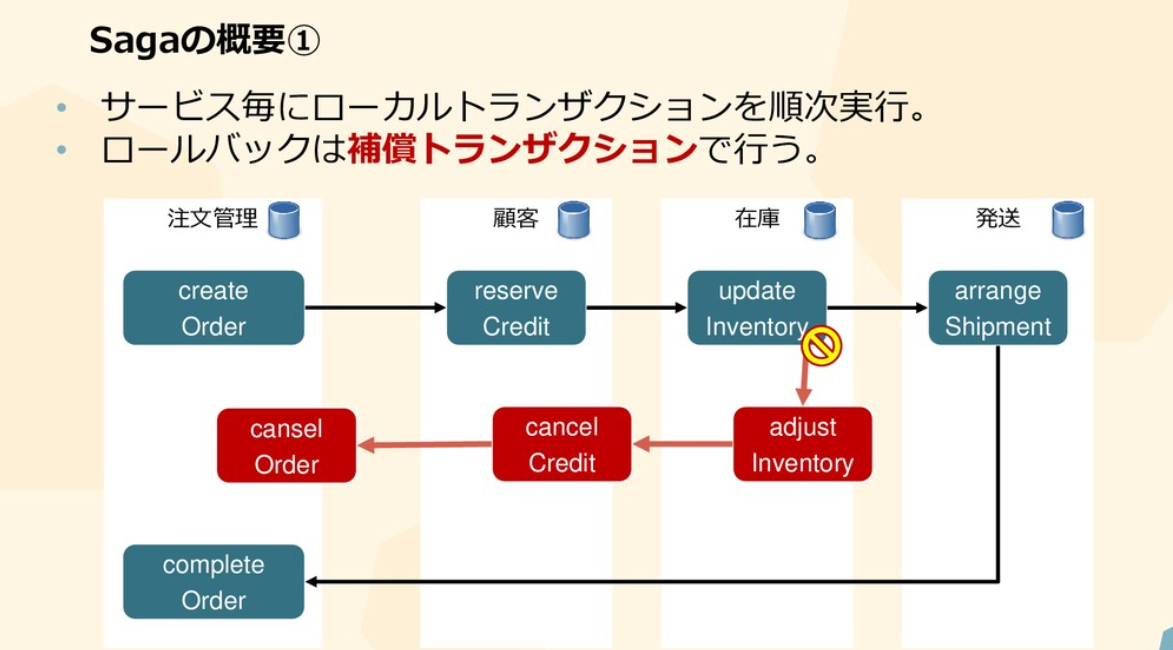
DDD関連
ドメイン
ドメインの目的とは何か?
- ドメインとはビジネスモデルをカプセル化したもの
- OOPでアクセッサーを経由してフィールドにアクセスするように、ビジネスモデルを独立するのが狙い
- その実態なドメインのモデル(エンティティ+値オブジェクト)やサービス(ドメインサービス)である
- エンティティはドメイン層の中で、JavaのPOJOのような基本的にどこにも依存しない作りにする
- DDDの思想としてビジネスロジックをFWから独立させるのが目的
- 例えば、RailsのModelにビジネスロジックを書き込むと、そのFWが終了した時に直せなくなる
- つまり、FWよりビジネスモデルの方がライフサイクルが長いので、ビジネスモデルをFWから切り離した構造になっている
- 故にデータを取得するのはRepository層が行い、データはエンティティとし、ドメインサービスでビジネスロジックを実行する
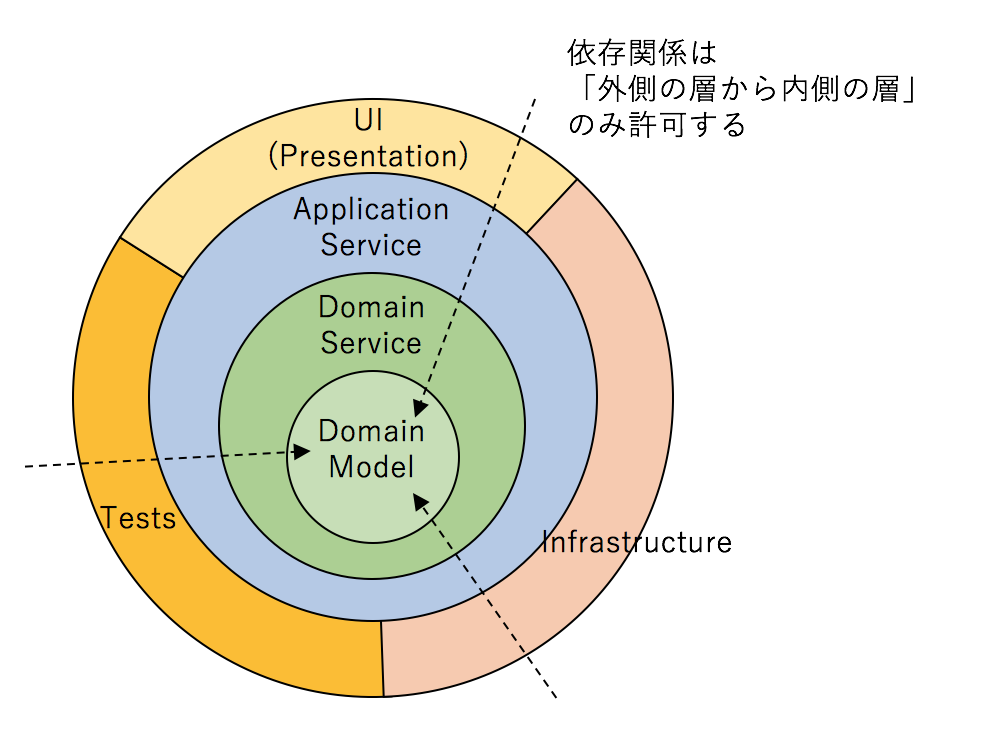
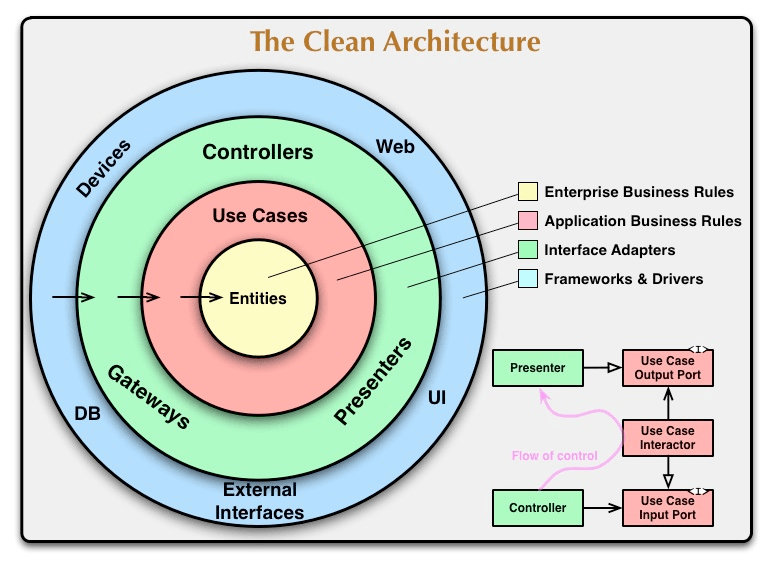
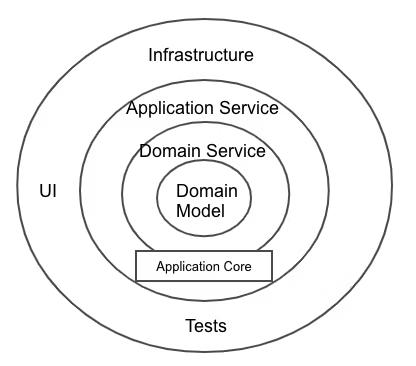
他のアーキテクチャとの比較
- コアにあるのはビジネスモデルをFWに依存させない事
- 故に、DDDでもクリーンアーキテクチャでもオニオンアーキテクチャでもドメインがコアにある
エンティティと値オブジェクト
エンティティ vs. 値オブジェクト
- エンティティ
- 値オブジェクトを複数もつストラクト(社員、記事、商品など)
- 値オブジェクト
- ストラクトの中の要素(名前、誕生日、体重など)

エンティティ
- 識別
- IDの識別子を持つ
- IDによる等価性
- フィールド
- フィールド名は自由
- フィールドの値の更新はできる
- ただし、値オブジェクトのフィールドの場合は、その値オブジェクトを再生成して詰める
- 例
- ユーザー、注文、製品など識別する必要があるもの
値オブジェクト
- 識別
- IDの識別子を持たない
- 値による等価性
- フィールド
- フィールドの値
- イミュータブル
- 更新はできない
- valueのフィールドを持つ
- 作成時にバリデーションが走る
- フィールドの値
- 例
- 住所、金額、日付範囲などの識別する必要がない値
モデルとは
DDDの定義だとモデルは大まかに次の関係にある。
$$ モデル = エンティティ + 値オブジェクト $$
ドメインイベントとドメインサービス
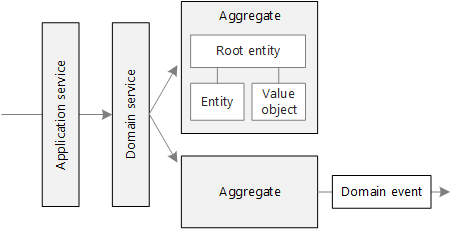
ドメインサービス (Domain Service)
- ドメインサービスは、エンティティや値オブジェクトに自然に属さないビジネスロジックをカプセル化するために使用されるサービス
- 具体的にはInputとOutputのDTOと、各種リポジトリを引数に撮り、ビジネスロジックを実行する
- ドメインサービスは、ドメインモデルの一部であり、アプリケーションのビジネスルールやビジネスプロセスの事
ドメインイベント (Domain Event)
- ドメインイベントは、システム内で発生した重要なビジネスイベントや状態の変化を表すオブジェクト
- 「注文が完了した(OrderCompleted)」や「顧客が登録された(CustomerRegistered)」など
- ドメインイベントは、その情報をシステムの他の部分に伝えるために使用されるDTO的なもの
DDDのレイヤーの名前の違い
層は次のような物がDDDやクリーンアーキテクチャでは利用される。
- プレゼンテーション層
- アプリケーション / ユースケース層
- ドメイン層
- インフラストラクチャ層
PoEAAでの鉄板
DAO vs. DTO
- DAO(Data Access Object)
- データベースやその他の永続化メカニズムへのアクセスを抽象化し、データアクセスロジックをカプセル化する事が目的
- 故にメソッドはCRUD関連のメソッドなどになる
- DTO(Data Transfer Object)
- 異なるソフトウェアの層やシステム間でデータを転送するためのコンテナ
- ネットワーク越しにデータを効率的に送受信するため、または異なる層間でのデータの受け渡しを簡素化するために使用される
DTO vs. エンティティ
- 一言で言うと、DTOはデータを移動差せる為のオブジェクト
- 他方、DDDのEntityはビジネスのモデルの写像
- 故に、レイヤー間をまたいで一時的に利用する用途の場合はDTOを使う
- 他方、ビジネスモデルを表現したドメインエンティティなどはエンティティを使う
- あくまで、DTOはコンテナにすぎない
アグリゲート
アグリゲートとは
- アグリゲート(Aggregate)は一貫性と整合性を維持するために一緒に管理されるべきエンティティと値オブジェクトのクラスター
- 簡単に言うと、RDBでいう値オブジェクトがカラム、エンティティがテーブルに対応するとき、アグリゲートはRDBでいうデータベースに対応する
- DBでも複数のテーブルで不整合がないように外部キー制約をかけるが、アグリゲートでもそれに近いことを行う
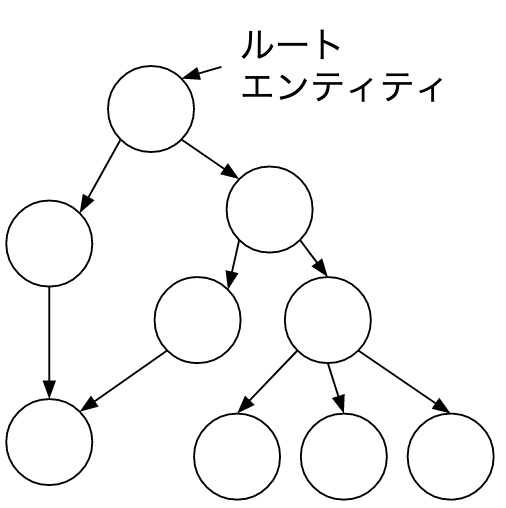
ルートエンティティ
- アグリゲートはエンティティの集合だがアクセスポイントとしてルートエンティティを持つ
- アグリゲートの一貫性を保証するためのビジネスルールを強制する
- RDBのようにグラフ構造ではないので、DDDでのアグリゲートはクラスター構造となる
- 故にアクセスポイントが必要となる
具体的な例
ドメインエンティティと値オブジェクトの例
前提
- 下はCustomerAnalysisのDomain Entityの例
- DBにはCustomer、User、UserProfileテーブルなどがある
- それらをドメインオブジェクト化したものが以下のEntity
- python 3.10を使用
- 画像解析も実際には下のような形でビジネスモデルを定義した
例
| |
次のように使用する。
| |
ドメインサービスの例
前提
エンティティ
- エンティティはドメインオブジェクトなので、基本的にどこにも依存しない作りにする
- DDDの思想としてビジネスロジックをFWから独立させるのが目的
- 例えば、MVCのようなFWの、Modelにビジネスロジックを書き込むとMVCのFWが終了した時に直せなくなる
- そこで。ビジネスモデルはドメイン層としてFWから分離したのがDDDの思想
リポジトリ
- インフラ層で定義するデータアクセッサー
- 実装はドメイン層のrepository_interfaceを参照する
- ドメインサービスの入力となる
- リポジトリ層の戻り値はエンティティになる
サービス
- DDDのサービスはいわゆるドメインサービスの事
- ドメインサービスでは少し特殊な形で用意する
- 具体的には、Repositoryに依存しないようにRepositoryを引数にとる関数となる
- ただし、型定義の際にRepositoryをImportするとRespository層に依存してしまうため、あくまでDomain層のRepository Interfaceを型にする
- また、入力と出力が煩雑になるため、InputDTOとOutputDTOを用意する
- 入力とシンプルにリポジトリとInput(DTO)を利用して実装された関数
- 具体的には外部のリポジトリを利用するが、ドメインサービスがリポジトリに依存しないようにIFとして型をとる
- 内部では、引数で渡った関数の入力とリポジトリーから取得したドメインエンティティを元に処理を行う
- サービスは基本的にビジネスロジックなのでビジネスロジックの言葉で書くのが正しい
- 例えばデータを保存するドメインサービスなどでは、トランザクションなどはドメインサービスを呼び出す側が処理するのが正しい
具体例
| |
DDDのLibのフォルダ設計例
前提
- AWSのCodeartifactを利用し、共通ライブラリをpython packageに分離した
- マイクロサービスで共通して使うため、libとして各サービスでimportするようにした
- 便宜上形式的に
__init__.pyは省略している
実例
フォルダの構成の具体例
| |
DDDのUsecaseの利用例
使い方は次のように使う。
| |
- usecase層では引数に撮らないが、ドメインサービスは独立するために、repositoryやinputなどを入力としてとるのがキモである
- なぜなら、ドメイン層はコアであり、他の層に依存してはいけないから
名前空間の設計例
前提
- 複数のlibの外部パッケージに分割し、共通の名前空間を利用した
- 具体的には、pythonのImplicit Namespace Packages機能を利用した
- pythonはフォルダに
__init__.pyを設置する必要がある - それを設置しないフォルダは、packageとして読み込めない
- ただし、
__init__.pyを設置すると、そのフォルダの初期化がかかってしまう - 故に複数のライブラリ、
aaa_libとbbb_libがあったとき共通のフォルダに__init__.pyを置くと先勝ちしてしまう - 例
xxx_pj/aaa_lib/main.pyとxxx_pj/bbb_lib/main.pyがあるとする- これらは別々のpythonのpackageであり、それぞれ
pip install aaa_lib bbb_libとしてインストールする - 両方の共通フォルダである
xxx_pjには__init__.pyが設置してある - 故に、
import aaa_libをすると、bbb_libは読み込めなくなってしまう - なぜなら、すでに
import aaa_libでxxx_pj/__init__.pyが初期化されるから - つまり、同じパッケージ名のものがあった場合は、先勝ちになってしまう
- そこで、
xxx_pjはimplicit namespace packageとして、xxx_pj/__init__.pyを置かず、pj全体の共通の名前空間を利用する - すると、
import aaa_libとimport bbb_libが問題なく行えるようになる - これは開発時のIDEの補完にも
xxx_pjから複数の別々のライブラリを読み込めるので、dx(dev experience)にも効果的である
具体例
下のように、共通するnamespaceには__init__.pyをおかないようにしている。
| |
結論
- 上記の通り、DDDでAIの解析システムを作るのは、以外と考える事が多い
- 他にもPrecommit、Lint、pytest、Dockernize、FastAPIのエラーの共通化やら色々なトピックがある
- ただ、少なくとも、プロダクトのライフサイクルに合わせて、ソフトウェア設計を見極めるべき
- ライフサイクルが短い => MVCでサクッと作る
- ライフサイクルが長い => DDDで重厚に作る
- 特に、必要最低限、疎結合かつDRYかつKISSに作るには一貫した設計が必要
参考文献
- pydantic/pydantic: Data validation using Python type hints
- 分散プログラミングモデルおよびデザインパターンの考察 - Yahoo! JAPAN Tech Blog
- ネット対戦型ゲームの通信方式でP2Pを採用したゲームは自前サーバーを介するよりも通信速度や安定性に問題が生じ易いですがそれは何故でしょうか? - Quora
- 集約(Aggregate)(DDD) - Linyclar
- エンタープライズアプリケーションアーキテクチャパターン
- API サーバを Rust で実装する 〜DDD/オニオンアーキテクチャによる実装検討〜 | OKAZAKI Shogo’s Website
- ドメイン駆動 + オニオンアーキテクチャ概略[DDD] - little hands' lab
- 戦術的 DDD を使用したマイクロサービスの設計 - Azure Architecture Center | Microsoft Learn
- オニオンアーキテクチャとは何か #設計 - Qiita
- DDDの各層について #Go - Qiita
- PEP 420 – Implicit Namespace Packages | peps.python.org
- 理解して拡げる分散システムの基礎知識 - Speaker Deck